Przyszłość dostępna już dzisiaj: architektura data lakehouse obsługiwana przez sztuczną inteligencję


Otwarte fundamenty Cloudera umożliwiają organizacjom uzyskiwanie dostępu do 100% ich danych, niezależnie od tego, gdzie się znajdują
W różnych branżach zespoły ds. danych opracowują na nowo sposób tworzenia i uruchamiania systemów, które nie tylko przechowują informacje: chcą przekształcić dane w analizę. Równie ważne jest to, że te systemy mają współdziałać. Modele sztucznej inteligencji, potoki funkcji, raporty business intelligence (BI) oraz zadania wsadowe często obejmują wiele zespołów i silników. Udostępnianie danych poza tymi granicami bez kopiowania lub refaktoryzacji jest teraz wymogiem o najwyższym znaczeniu.
Tradycyjnie organizacje polegały na architekturze dwuwarstwowej: hurtowniach danych zoptymalizowanych pod kątem BI i raportowania oraz jeziorach danych zaprojektowanych pod kątem sztucznej inteligencji i uczenia maszynowego (ML) na dużą skalę. To oddzielenie wiązało się z kosztami: złożony przepływ danych, specjalistyczna inżynieria i zduplikowane przechowywanie w systemach, które rzadko były zsynchronizowane.
Otwarta architektura lakehouse firmy Cloudera rozwiązuje ten problem, łącząc obciążenia analityczne (BI, zapytania ad-hoc) i sztucznej inteligencji (predykcyjna i generatywna AI lub GenAI) w jednym, zarządzanym fundamencie danych. Dzięki otwartym formatom tabel, takim jak Apache Iceberg, ta ujednolicona architektura danych umożliwia organizacjom przeniesienie obliczeń do danych (a nie na odwrót) i zapewnia fundament do uruchamiania obciążeń AI bliżej danych. Obciążenia AI w architekturze lakehouse mogą operować bezpośrednio na danych zarządzanych, wersjonowanych i wysokiej jakości.
Cloudera to jedyna firma oferująca platformę danych i sztucznej inteligencji, która wprowadza AI do danych w każdym miejscu. Wykorzystując nasze sprawdzone fundamenty open source, zapewniamy spójne środowisko chmurowe stanowiące połączenie chmur publicznych, centrów danych i krawędzi sieci.
Znaczenie otwartych fundamentów dla uruchamiania obciążeń AI
W ciągu ostatniej dekady przedsiębiorstwa nauczyły się, że sama wydajność i skalowalność nie wystarczą, a o długoterminowym sukcesie decydują elastyczność i interoperacyjność. Zwłaszcza obciążenia AI zależą od możliwości korzystania z różnych źródeł danych, struktur i narzędzi bez ograniczeń wynikających z zastrzeżonych formatów lub systemów.
Właśnie tutaj otwarte formaty tabel, takie jak Apache Iceberg, przekształciły architekturę platform danych. Iceberg oddziela logiczną definicję tabeli od jej układu w pamięci fizycznej, umożliwiając wielu silnikom i strukturom odczytywanie i zapisywanie tych samych danych z pełnymi gwarancjami transakcyjnymi. Ta otwartość umożliwia rozwijanie infrastruktury i wdrażanie nowych silników obliczeniowych bez przepisywania potoków.
Uruchamianie potoków klasy produkcyjnej wymaga ujednoliconej platformy, która może łączyć dane, modele i zarządzanie na każdym etapie cyklu życia sztucznej inteligencji. Podstawą są potoki inżynierii danych i funkcji, które stale przekształcają surowe ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane dane w funkcje gotowe na sztuczną inteligencję z zachowaniem pochodzenia i powtarzalności na potrzeby trenowania i oceny modelu.
Poza tradycyjnym ML GenAI wprowadza nowe wymagania operacyjne. Zespoły potrzebują infrastruktury i dostępu do danych do generowania wspomaganego wyszukiwaniem (RAG), dostrajania dużych modeli językowych (LLM) na danych prywatnych oraz tworzenia agentowych przepływów pracy, które łączą modele, polecenia i protokoły kontekstu modelu (MCP) (interfejsy API) w celu wykonywania zadań specyficznych dla danej dziedziny. Te obciążenia bazują zarówno na danych tabelarycznych, jak i nieustrukturyzowanych (tekst, dokumenty, obrazy i osadzenia) — wszystkich zarządzanych w ramach jednej płaszczyzny danych i metadanych. Ponadto skalowalna warstwa wnioskowania jest niezbędna do bezpiecznego i wydajnego wdrażania tych modeli oraz ich obsługiwania.
Ponieważ obciążenia AI stają się coraz bardziej wielomodalne i agentowe, równie krytyczny staje się dostęp do katalogów i metadanych. Potoki sztucznej inteligencji, systemy pobierania i autonomiczni agenci korzystają z metadanych do odnajdywania zbiorów danych, odtwarzania stanów trenowania i utrzymywania pochodzenia. Otwarty katalog zapewnia uniwersalny sposób, dzięki któremu te systemy mogą wyszukiwać, rejestrować i śledzić zbiory danych — niezależnie od tego, gdzie i jak są one przetwarzane.
Otwarte fundamenty Cloudera umożliwiają organizacjom obsługę pełnego spektrum obciążeń analitycznych, predykcyjnych i GenAI.
Platforma ujednoliconych danych i sztucznej inteligencji firmy Cloudera
Otwarta architektura data lakehouse firmy Cloudera łączy inżynierię danych, analitykę i sztuczną inteligencję w tej samej zarządzanej architekturze, opierając się na otwartych fundamentach, takich jak Apache Iceberg i REST Catalog. Platforma została zaprojektowana zgodnie z zasadą, że obciążenia (analityczne lub sztucznej inteligencji) powinny operować tam, gdzie dane już się znajdują. Eliminując zakłócenia związane z przenoszeniem lub duplikowaniem danych, zespoły mogą tworzyć ciągłe potoki obejmujące operacje pozyskiwania, transformacji, analizy i modelowania z pełnym ustalaniem pochodzenia i zarządzaniem.
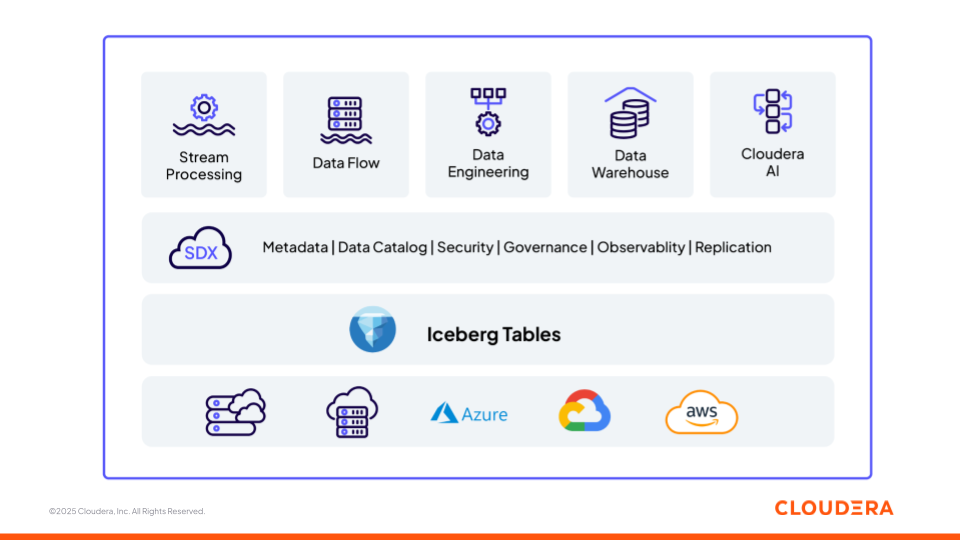
Rysunek 1. Platforma danych i sztucznej inteligencji firmy Cloudera oparta na otwartych fundamentach (Apache Iceberg)
Teraz przyjrzymy się, jak różne komponenty platformy Cloudera (rysunek 1) wspierają zespoły w budowaniu potoków ML i aplikacji GenAI, a także na różnych etapach cyklu życia danych i sztucznej inteligencji — od pozyskiwania do wnioskowania — działając przy tym jako jedna, interoperacyjna platforma. Każdy komponent jest zbudowany na otwartych standardach, zapewniając elastyczność i interoperacyjność w różnych środowiskach.
Składowanie: Apache Iceberg
Apache Iceberg to otwarty, wersjonowany i transakcyjny format tabel, który stanowi podstawę architektury lakehouse firmy Cloudera. Iceberg umożliwia ewolucję schematu, podróże w czasie i operacje atomowe, pozwalając na stałe operowanie zarówno obciążeń analitycznych, jak i AI na tych samych zarządzanych danych. Cloudera oferuje zarządzane i wersjonowane fundamenty, które zapewniają, że każdy model, każde polecenie lub zadanie pobierania czerpie ze spójnego i identyfikowalnego widoku danych.
Natywne funkcje Iceberg, takie jak ewolucja schematów, są również ściśle zgodne z ewolucją zbiorów danych sztucznej inteligencji. Magazyny funkcji, zbiory danych do trenowania i korpusy wyszukiwania mogą współdzielić te same tabele Iceberg w architekturze lakehouse firmy Cloudera, używając migawek do zamrażania spójnych widoków na potrzeby trenowania, podczas gdy wciąż napływają nowe dane do wnioskowania. Eliminuje to podział między tabelami analitycznymi a pamięcią masową specyficzną dla sztucznej inteligencji.
Pozyskiwanie: dane w ruchu Cloudera
Platforma Cloudera DataFlow, utworzona na podstawie Apache NiFi, stanowi fundament dla ciągłego przepływu danych do architektury lakehouse. Umożliwia pozyskiwanie z niskim opóźnieniem z różnych źródeł przedsiębiorstwa — baz danych, interfejsów API, urządzeń IoT i dzienników zdarzeń — w celu obsługi obciążeń wsadowych i strumieniowych. Najnowsze innowacje w zakresie natywnej integracji Apache Iceberg firmy NiFi pozwalają teraz na zapisywanie danych bezpośrednio w otwartej architekturze lakehouse bez przetwarzania pośredniego. To ścisłe powiązanie między NiFi i Iceberg redukuje złożoność potoku i przybliża pozyskiwanie do otwartego formatu tabeli.
W przypadkach użycia w czasie rzeczywistym NiFi, Apache Kafka i Apache Flink tworzą strukturę pozyskiwania sterowaną zdarzeniami: NiFi orkiestruje dane i kieruje je, Kafka zapewnia trwałe przesyłanie strumieniowe, a Flink umożliwia wzbogacanie danych w czasie rzeczywistym przed ich utrwaleniem w systemie Iceberg. Taki projekt zapewnia, że dane pozostają zarówno świeże, jak i zarządzane u wszystkich dalszych konsumentów. Ten ciągły przepływ danych multimodalnych jest również tym, co napędza obciążenia AI w architekturze lakehouse. Dzięki ciągłemu udostępnianiu danych w czasie rzeczywistym w tabelach Iceberg pod spójnym zarządzaniem przedsiębiorstwa mogą dostarczać systemom GenAI aktualnych informacji specyficznych dla danej dziedziny, co sprawia, że potoki RAG i agentowe przepływy pracy są bardziej precyzyjne, ugruntowane i niezawodne.
Katalog: Cloudera Iceberg REST Catalog
Cloudera Iceberg REST Catalog (oparty na otwartej specyfikacji REST) zapewnia scentralizowaną i interoperacyjną usługę metadanych, która umożliwia dowolnemu silnikowi innej firmy (takiemu jak Snowflake, Redshift i Databricks) obsługującemu otwartą specyfikację, mieć dostęp do tabel Iceberg bez kopiowania. Jest to kluczowy aspekt dla organizacji, ponieważ nie ograniczają się one tylko do jednego silnika obliczeniowego oferowanego przez jedną platformę, a zatem mają elastyczność w wyborze najlepszych obliczeń dla zadania. Użytkownicy mogą korzystać z preferowanych narzędzi, podczas gdy te same zasady bezpieczeństwa i zarządzania oferowane przez Cloudera podążają za danymi do każdego miejsca, zapewniając spójność w różnych środowiskach.
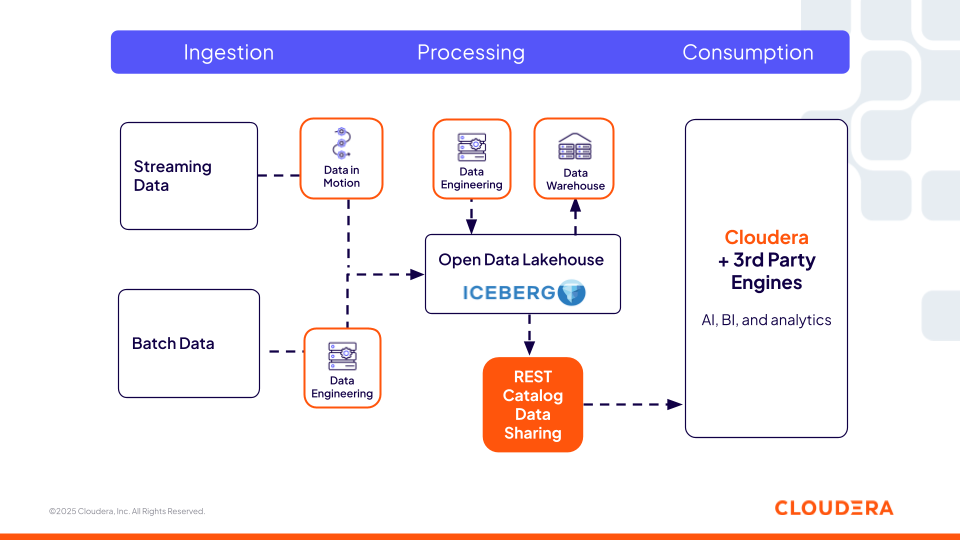
Rysunek 2. Iceberg REST Catalog firmy Cloudera umożliwia interoperacyjność z silnikami innych firm
Ta warstwa katalogu jest krytyczna dla potoków inżynierii funkcji, agentowych przepływów pracy i systemów pobierania w celu dynamicznego lokalizowania i uzyskiwania dostępu do zarządzanych zbiorów danych. Agenci AI mogą przeszukiwać tabele Iceberg za pomocą katalogu REST Catalog, tak jak wykresu wiedzy danych przedsiębiorstwa. Mogą odnajdywać dostępne tabele, interpretować ich schematy i wnioskować na podstawie metadanych tabeli, takich jak partycjonowanie, migawki i pochodzenie, aby określić, których zbiorów danych użyć.
Bezpieczeństwo i zarządzanie: Cloudera SDX
Cloudera Shared Data Experience (SDX) to ujednolicona struktura zabezpieczeń i zarządzania obejmująca wszystkie usługi — od pozyskiwania po wnioskowanie. SDX zapewnia pojedynczą, spójną warstwę dla ustalania pochodzenia danych, audytu, kontroli dostępu i egzekwowania zasad, zapewniając, że każde obciążenie dziedziczy ten sam model zabezpieczeń niezależnie od tego, gdzie jest uruchamiane. Integruje się z systemami tożsamości przedsiębiorstwa (LDAP, SSO, OAuth) i obsługuje precyzyjną kontrolę dostępu na podstawie ról i atrybutów w danych ustrukturyzowanych i nieustrukturyzowanych.
Łącząc SDX z fundamentem otwartej architektury lakehouse, firma Cloudera zapewnia, że dane, modele i agenci AI działają w ramach tej samej zarządzanej granicy, zapewniając przejrzystość, powtarzalność i zaufanie zarówno dla obciążeń analitycznych, jak i GenAI.
Usługi danych i sztucznej inteligencji Cloudera
Warstwa ujednoliconych usług łączy wszystkie możliwości funkcjonalne, których zespoły potrzebują do przekształcania, analizy i operacjonalizacji sztucznej inteligencji, a wszystko to podczas pracy nad tymi samymi zarządzanymi danymi.
Data Engineering
Rozwiązanie Cloudera Data Engineering, oparte na rozwiązaniach open source Apache Spark i Apache Airflow, zapewnia bezserwerową usługę tworzenia, orkiestrowania i skalowania potoków danych bezpośrednio w tabelach Iceberg, co umożliwia niezawodne, powtarzalne potoki ETL i funkcji dla obciążeń analitycznych i AI w środowiskach hybrydowych.
Usługi sztucznej inteligencji
Warstwa usług sztucznej inteligencji Cloudera operacjonalizuje pełny cykl życia sztucznej inteligencji, począwszy od trenowania i dostrajania modelu do bezpiecznego wdrażania — wszystko to jest uruchamiane natywnie na tym samym, zarządzanym fundamencie danych z Iceberg. Jednoczy to tworzenie modelu, rejestr i wnioskowanie w jeden przepływ pracy, który łączy inżynierię danych i operacje AI.
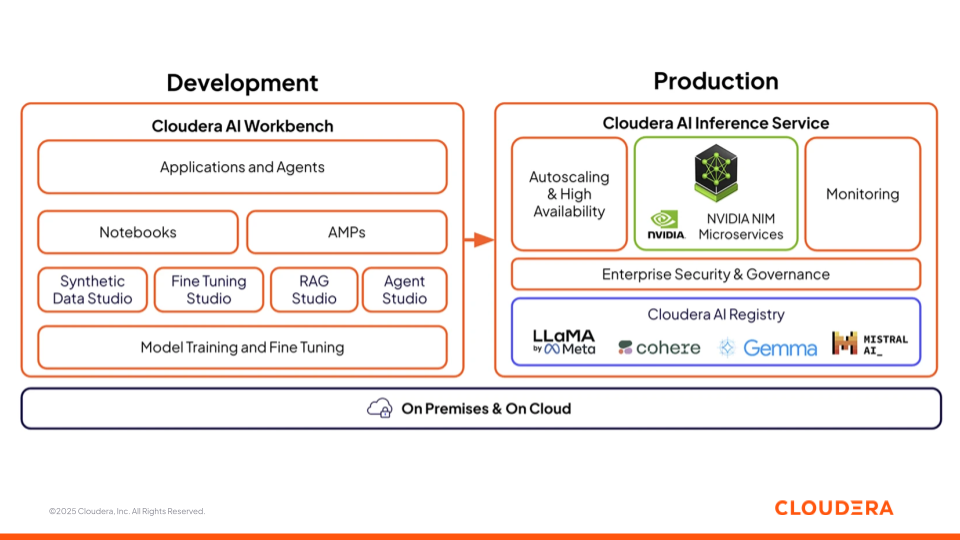
Rysunek 3. Oferta sztucznej inteligencji Cloudera z AI Workbench i usługą wnioskowania
Cloudera AI Workbench
Cloudera AI Workbench to środowisko współpracy, w którym badacze danych, analitycy i inżynierowie opracowują, dostrajają i testują modele. Łączy w sobie notesy, konstruktory aplikacji o niskim użyciu kodu (akceleratory AMP) oraz specjalistyczne studia dla każdego etapu rozwoju sztucznej inteligencji. Aby przyspieszyć rozwój i wdrażanie sztucznej inteligencji, Cloudera AI Workbench stanowi podstawę dla czterech studio sztucznej inteligencji, które eliminują lukę między zespołami biznesowymi i technicznymi, sprzyjając współpracy nad projektami AI.
- Synthetic Data Studio generuje syntetyczne zbiory danych do testowania i trenowania modeli, gdy ilość danych rzeczywistych jest niewielka lub ograniczona.
- Fine-Tuning Studio dostosowuje modele z otwartymi fundamentami do zbiorów danych specyficznych dla danego przedsiębiorstwa, zapewniając wyższą trafność i dokładność.
- RAG Studio buduje potoki RAG, które łączą modele LLM (takie jak OpenAI, Anthropic, Amazon Bedrock) z odpowiednimi danymi prywatnymi w celu uzyskania osadzonych, kontekstowych rezultatów.
- Agent Studio umożliwia tworzenie wieloetapowych, agentowych przepływów pracy, które wykorzystują modele, MCP, API i wewnętrzne źródła danych do automatyzacji zadań specyficznych dla danej dziedziny.
Wszystkie te funkcje działają na otwartej architekturze lakehouse (na fundamentach Iceberg), dając zespołom zarządzany dostęp bez kopiowania do danych potrzebnych do określonych zadań.
Serwer Cloudera MCP Server
Cloudera rozszerza także otwartość swojej platformy sztucznej inteligencji poprzez serię nowych usług MCP, zaczynając od Cloudera AI Workbench MCP Server typu open source. Ta usługa jest przeznaczona do integracji systemu sztucznej inteligencji, umożliwiając funkcje wywoływania agentów i narzędzi w ramach AI Workbench. Zapewnia strukturę dla modeli LLM do bezpiecznej interakcji z funkcjami i komponentami Cloudera AI Workbench, przenosząc modele, dane i aplikacje do zautomatyzowanych przepływów pracy w przedsiębiorstwie. W ramach tej architektury inteligentni agenci mogą wnioskować, działać i automatyzować zadania w zaufanym, zarządzanym środowisku Cloudera, jednocześnie zapewniając bezpieczeństwo, kontrolę i możliwości audytu wymagane w regulowanych branżach.
Cloudera AI Inference Service
Usługa Cloudera AI Inference Service wprowadza modele do produkcji z automatycznym skalowaniem, wysoką dostępnością i kompleksową obserwowalnością. Wspiera zarówno tradycyjne modele ML, jak i duże modele językowe (LLM), obsługując prognozy i odpowiedzi z niskim opóźnieniem. Modele mogą być wdrażane jako punkty końcowe REST lub gRPC z zabezpieczeniami klasy korporacyjnej, co zapewnia niezawodny i spójny dostęp z aplikacji oraz agentów.
Rejestr Cloudera AI Registry, zintegrowany z warstwą wnioskowania, dostarcza scentralizowanego zarządzania cyklem życia modelu z interfejsami API zgodnymi z MLflow do śledzenia, wersjonowania, przechowywania artefaktów i ustalania pochodzenia. Można wybierać spośród różnych opcji otwartych i korporacyjnych modeli językowych, takich jak LlaMa, Cohere, Gemma, Mistral.
Warstwa wnioskowania obejmuje również wbudowane monitorowanie i obserwowalność, umożliwiając zespołom śledzenie opóźnień, przepustowości i dryfu modelu przy jednoczesnym zachowaniu pełnego ustalania pochodzenia i zgodności dzięki zarządzaniu SDX. Zapewnia to, że przewidywania modelu są wyjaśnialne i identyfikowalne, co jest kluczowym wymogiem dla sztucznej inteligencji klasy korporacyjnej.
Przyszłość jest napędzana przez sztuczną inteligencję, a sztuczną inteligencję napędzają wszystkie dane
Sukces sztucznej inteligencji zależy zarówno od architektury danych, jak i od możliwości modelu/agenta. Lakehouse zapewnia tę podstawę, ujednolicając obciążenia analityczne, operacyjne i AI na jednej, zarządzanej płaszczyźnie danych. Korzystanie z otwartych standardów zapewnia, że dane, metadane i modele mogą współpracować między różnymi narzędziami, chmurami i zespołami bez przeszkód.
Cloudera AI Workbench, AI Inference Service i zintegrowany rejestr AI Registry razem uzupełniają cykl życia od danych do sztucznej inteligencji na otwartej platformie lakehouse. Ten stos, zbudowany bezpośrednio na zarządzanych tabelach Iceberg i otwartym dostępie do metadanych, zapewnia, że każdy model, każde polecenie i każdy agent operują na zaufanych, wersjonowanych danych.
Przyszłość korporacyjnej sztucznej inteligencji nie będzie zdefiniowana przez zastrzeżone stosy, ale przez otwarte fundamenty, które ujednolicają dane, zarządzanie i analizę poprzez wspólne standardy i przejrzystą interoperacyjność.
Aby dowiedzieć się więcej o tym, jak bezpiecznie przygotowywać, integrować i analizować dane na dużą skalę z Cloudera, zapoznaj się z naszymi prezentacjami produktów lub zarejestruj się na bezpłatną 5-dniową wersję próbną.