Demokratyzacja danych na potrzeby sztucznej inteligencji dzięki interoperacyjności między silnikami i współpracy nad danymi bez kopiowania




Jak katalog Cloudera Iceberg REST Catalog zwiększa możliwości otwartych przedsiębiorstw gotowych na sztuczną inteligencję
Interoperacyjność od dawna była modnym słowem, a nie zdolnością, na której w praktyce mogą polegać przedsiębiorstwa. Zamiast tego architekci danych często łączą ze sobą pofragmentowane systemy, kierownicy ds. obsługi danych stają w obliczu ogromnego ryzyka i uzależnienia od dostawcy z powodu silosowego zarządzania, a liderzy platform mają ograniczone możliwości zapewnienia spójnego widoku danych swoim zespołom. Niezależnie od tego, czy powodem są fuzje, strategie wielochmurowe, czy partnerstwa zewnętrzne, wzorzec powtarza się: rosnące koszty, wolniejsze innowacje i ograniczona zdolność do skalowania z pewnością sztucznej inteligencji.
W firmie Cloudera pomagaliśmy naszym klientom przezwyciężać te wyzwania — rozłączone warstwy metadanych, zduplikowane potoki danych oraz modele zarządzania, które nie obejmują wszystkich narzędzi — zawsze dążąc do zwiększania możliwości otwartych, gotowych na sztuczną inteligencję przedsiębiorstw, które odblokowują interoperacyjność na dużą skalę.
Dlaczego otwartość ma znaczenie dla sztucznej inteligencji w przedsiębiorstwie
Aby skalować obciążenia AI, organizacje potrzebują pełnej widoczności i kontroli nad danymi stanowiącymi podstawę ich działalności. Analiza metadanych odgrywa kluczową rolę w tym równaniu, umożliwiając organizacjom zrozumienie, gdzie znajdują się dane, jak są ustrukturyzowane i jak są wykorzystywane w zespołach oraz narzędziach.
Dzięki otwartym standardom, takim jak Apache Iceberg i Iceberg REST Catalog, przedsiębiorstwa zyskują ujednoliconą warstwę metadanych, która obsługuje udostępnianie danych bez ETL, wymusza zarządzanie oraz zapewnia bezpieczną interoperacyjność między silnikami analiz i sztucznej inteligencji. Ta podstawa przekształca pofragmentowaną infrastrukturę w połączoną architekturę danych gotową na sztuczną inteligencję — taką, w której metadane stają się kluczem do przyspieszania dostępu do analiz z jednoczesnym utrzymaniem zaufania.
Otwarte, bezpieczne i proste: Cloudera Iceberg REST Catalog
Standard Cloudera Iceberg REST Catalog obsługuje naszą otwartą architekturę data lakehouse i pomaga organizacjom uprościć architekturę, zmniejszyć powielanie oraz rozszerzyć bezpieczny dostęp do danych, gdziekolwiek jest on potrzebny.
Pełni rolę uniwersalnej, interoperacyjnej warstwy metadanych i zapewnia dostęp bez kopiowania do tabel Iceberg w różnych narzędziach, chmurach i zespołach, umożliwiając narzędziom typu open source i narzędziom innych firm uzyskiwane dostępu do tych samych danych. Funkcje i korzyści są następujące:
- Otwarte i niezależne od silnika: udostępnia interfejsy API oparte na standardach, które obsługują narzędzia, takie jak Athena, Databricks, Redshift i Snowflake — umożliwiając interoperacyjność bez uzależniania od dostawcy
- Oddzielone z założenia: abstrahuje silniki zapytań od magazynów metastore zaplecza, zmniejszając złożoność i zwiększając przenośność między środowiskami
- Dostęp do metadanych w czasie rzeczywistym: obsługuje szybkie, aktualne zapytania o metadane z magazynów metastore zgodnych z Iceberg, poprawiając widoczność danych w zespołach
- Zarządzane i bezpieczne: rozszerza szczegółowe kontrole dostępu, uprawnienia na poziomie wiersza oraz integrację z zarządzaniem tożsamościami i dostępem (IAM) w przedsiębiorstwie (takie jak LDAP i OAuth2) na wszystkie połączone systemy — zapewniając spójne egzekwowanie zasad na dużą skalę
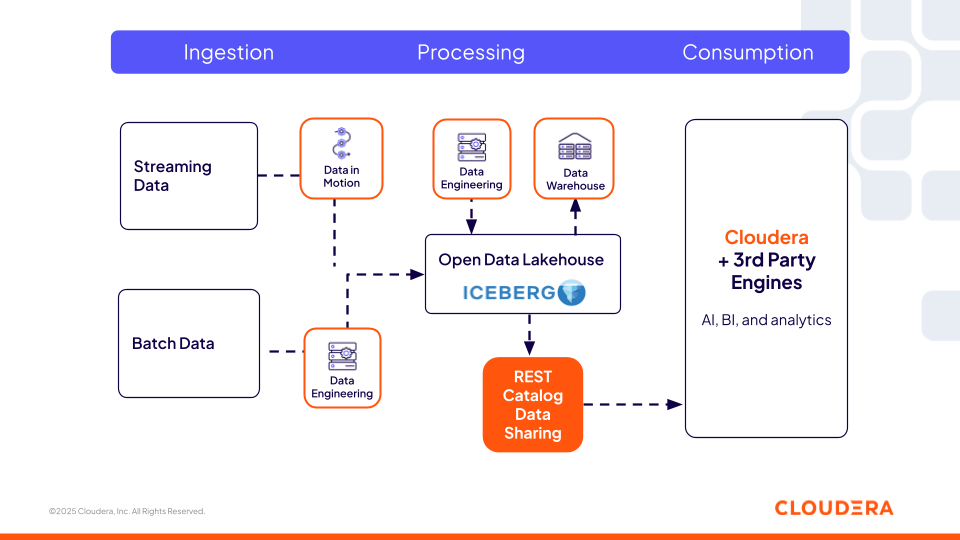
Rysunek 1. Standard Iceberg REST Catalog firmy Cloudera zapewnia uniwersalną, interoperacyjną warstwę metadanych, umożliwiając narzędziom open source i narzędziom innych firm uzyskiwanie dostępu do tych samych danych.
Rzeczywiste przypadki użycia i wpływ standardu Iceberg REST Catalog
Poniższe realne przykłady ilustrują, jak organizacje używają standardu Iceberg REST Catalog do upraszczania stosu danych, obniżania całkowitego kosztu posiadania (TCO) i skracania czasu potrzebnego do uzyskania wartości — wszystko to przy utrzymaniu danych w ich właściwym miejscu.
Wszystkie te przykłady pokazują, jak otwarte i interoperacyjne podejście Cloudera przyspiesza uzyskiwanie wyników AI, zwiększa wydajność operacyjną w skali przedsiębiorstwa oraz zapewnia bezpieczeństwo i zgodność z przepisami.
Udostępnianie danych: skalowanie aplikacji AI do ponad 3000 użytkowników wieloplatformowych
Producent luksusowych samochodów napotykał coraz większe wyzwania związane z bezpiecznym udostępnianiem danych partnerowi zewnętrznemu przy użyciu Databricks. Metody tradycyjne były oparte na duplikowaniu danych, co powodowało wzrost kosztów, złożoności i brak elastyczności architektonicznej.
Dzięki wdrożeniu standardu Iceberg REST Catalog klient zapewnił bezpieczne udostępnianie danych bez ETL zarówno w systemach wewnętrznych, jak i na platformach zewnętrznych. To otwarte, oparte na standardach podejście pozwoliło mu wybrać najlepsze narzędzia do danego zadania — Spark do złożonych potoków danych oraz Impala do szybkiej analizy SQL. Dzięki temu firma skalowała aplikacje AI do ponad 3000 użytkowników, zachowując przy tym pełne zarządzanie i kontrolę nad dostępem do danych.
Optymalizacja Data Warehouse: obniżenie kosztów przenoszenia danych o 74%
Po fuzji globalna firma satelitarna napotkała poważne przeszkody w ujednolicaniu pofragmentowanych danych zablokowanych w zastrzeżonych systemach. Bez spójnej, interoperacyjnej warstwy danych jej inicjatywy w zakresie sztucznej inteligencji i analizy były powolne w skalowaniu i trudne w zarządzaniu.
Otwarta architektura data lakehouse firmy Cloudera, obsługiwana przez standard Iceberg REST Catalog, pomogła klientowi skonsolidować te silosy i ustanowić jedno źródło danych dla wszystkich obciążeń związanych ze sztuczną inteligencją i analizą. Wysyłając zapytania do zarządzanych tabel Iceberg bezpośrednio w S3, wyeliminowano potrzebę stosowania nadmiarowych potoków danych i zmiany platformy, co doprowadziło do obniżenia o 74% kosztów przenoszenia danych.
Pokaz: bliższe spojrzenie na udostępnianie danych za pośrednictwem standardu Iceberg REST Catalog firmy Cloudera
Ten interaktywny pokaz ożywia standard Iceberg REST Catalog poprzez scenariusz dla usług finansowych. W fikcyjnym banku Parent Bank różne zespoły używają swoich ulubionych narzędzi — takich jak Snowflake i AWS Athena — do bezpiecznego uzyskiwania dostępu do jednego zarządzanego źródła danych, bez stosowania złożonych procesów ETL ani kosztownego przenoszenia danych.
Aby dogłębniej poznać tę ofertę i korzyści, jaki może ona przynieść Twojej organizacji, zapoznaj się z tymi zasobami:
- Odwiedź naszą stronę produktu, aby dowiedzieć się więcej o otwartej architekturze data lakehouse firmy Cloudera.
- Przeczytaj komunikat prasowy, aby zapoznać się z pełną treścią oświadczenia na temat wizji otwartego udostępniania danych firmy Cloudera.