Cloudera Streaming
Skorzystaj z potencjału rozwiązań Apache Kafka i Apache Flink, aby tworzyć wydajne usługi i aplikacje działające w czasie rzeczywistym.

OGÓLNE INFORMACJE
Twój fundament do tworzenia aplikacji w czasie rzeczywistym.
Rozwiązanie Cloudera Streaming jest przeznaczone do zastosowań o kluczowym znaczeniu. Wykorzystując Apache Kafka i Apache Flink do przetwarzania danych w czasie rzeczywistym, obsługuje miliony zdarzeń na sekundę przy niskim opóźnieniu i gwarantowanej spójności.
Przyspiesz tworzenie aplikacji, umożliwiając zespołom łatwe tworzenie niezawodnych potoków na potrzeby modeli ML w czasie rzeczywistym i zaawansowanej analityki predykcyjnej.
Twórz, testuj i wdrażaj aplikacje do przesyłania strumieniowego spójnie, bezpiecznie i z zarządzaniem w środowiskach lokalnych lub chmurowych.
Twórz szybsze i bezpieczniejsze aplikacje do zarządzania danymi i analityczne przy optymalnej wydajności i skalowalności w dowolnym miejscu.
PRZYKŁADY ZASTOSOWANIA
Włącz aplikacje, które napędzają Twój biznes.
-
Wykrywanie oszustw w czasie rzeczywistym
Twórz mikrousługi, które analizują strumienie transakcji w czasie rzeczywistym.
-
Dynamiczna obsługa klienta
Twórz aplikacje oparte na zdarzeniach, które działają na podstawie danych interakcji natychmiast po ich utworzeniu.
-
Konserwacja predykcyjna i zoptymalizowane procesy przemysłowe
Twórz aplikacje, które pozyskują i analizują dane o dużym wolumenie z podłączonych urządzeń.
-
Bezpieczeństwo dostosowane do wymagań korporacji
Zabezpieczaj cykl życia danych i zarządzaj nim poprzez integracje z większą platformą Cloudera.
-
Wykrywanie oszustw w czasie rzeczywistym
Twórz mikrousługi, które analizują strumienie transakcji w czasie rzeczywistym.
-
Dynamiczna obsługa klienta
Twórz aplikacje oparte na zdarzeniach, które działają na podstawie danych interakcji natychmiast po ich utworzeniu.
-
Konserwacja predykcyjna i zoptymalizowane procesy przemysłowe
Twórz aplikacje, które pozyskują i analizują dane o dużym wolumenie z podłączonych urządzeń.
-
Bezpieczeństwo dostosowane do wymagań korporacji
Zabezpieczaj cykl życia danych i zarządzaj nim poprzez integracje z większą platformą Cloudera.

Wykorzystaj gwarantowane dostarczanie Kafka i przetwarzanie stanowe Flink do modelowania i zwalczania złożonych, zmieniających się zagrożeń oszustwami.
Twórz zaawansowane aplikacje wymagające stanu, kontekstu i złożonego przetwarzania zdarzeń w celu oceniania modelu w czasie rzeczywistym.
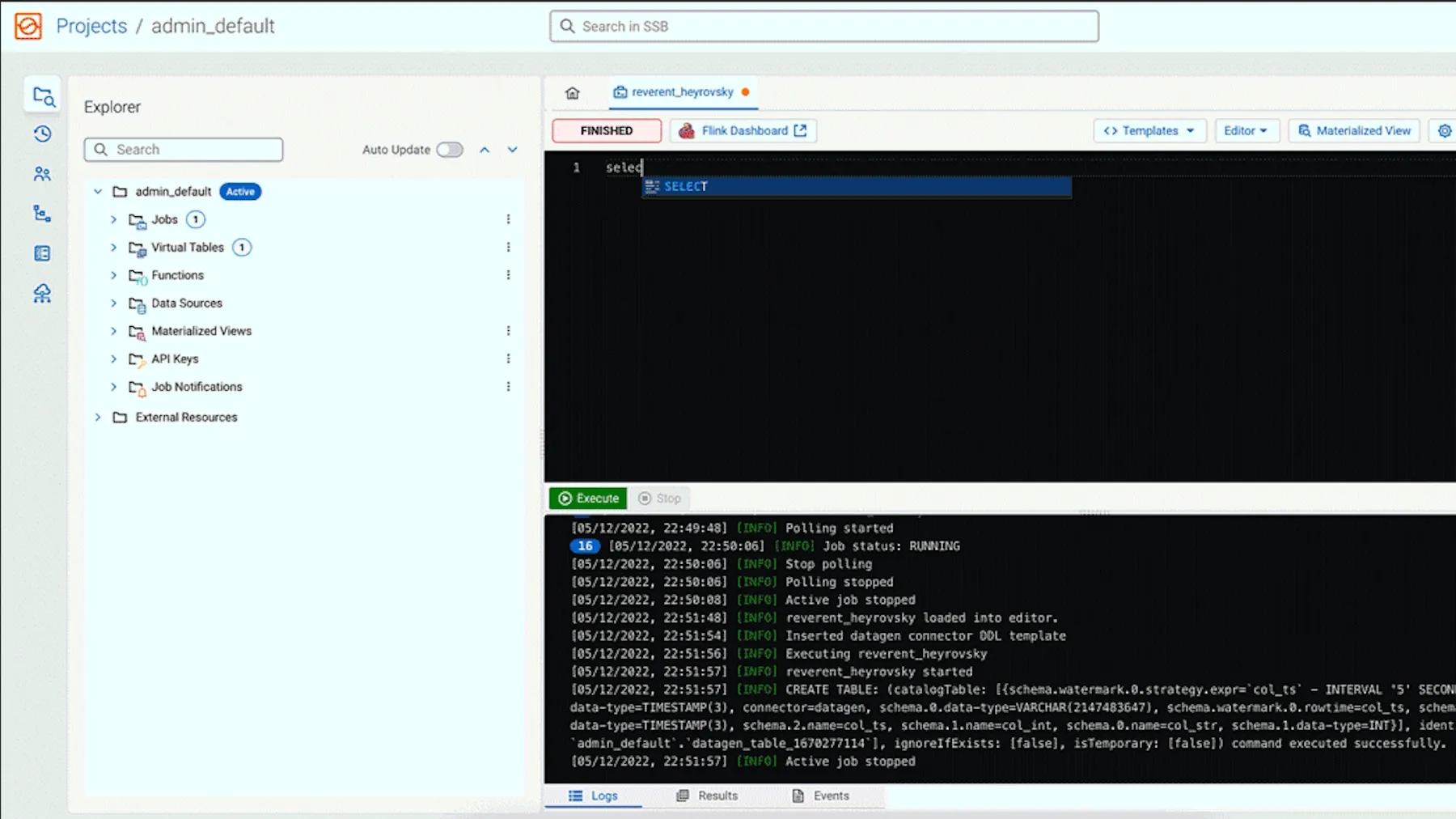
Twórz oferty na bieżąco, dynamiczne rekomendacje i proaktywne aplikacje usług za pomocą narzędzia Cloudera SQL Stream Builder.
Umożliw analitykom korzystanie z języka SQL na strumieniach Flink na żywo, co pozwala na personalizację w czasie rzeczywistym i natychmiastowe podejmowanie decyzji o kolejnych najlepszych działaniach dla klientów.

Przetwarzaj złożone strumienie IoT, identyfikuj najważniejsze wskaźniki awarii i wyzwalaj automatyczne odpowiedzi.
Nasi operatorzy dla rozwiązań Kafka i Flink automatyzują wdrażanie i skalowanie, zwalniając Twoje zespoły i umożliwiając im skupianie się na logice aplikacji.
Rozwiązanie Cloudera SDX chroni wszystkie dane w ruchu, zapewniając ich jakość i spójność.
Zapewnij zespołom operacyjnym kompleksowe narzędzia monitorujące, które pozwalają im kontrolować dostęp do danych i zarządzanie nimi.
Intuicyjny interfejs do tworzenia i testowania zadań Flink SQL oraz zarządzania nimi. Przyspiesza cykle rozwojowe i umożliwia szerszemu gronu użytkowników technicznych tworzenie niezawodnych aplikacji streamingowych.
Platforma analityki na strumieniu danych firmy Cloudera, oparta na wiodącym w branży silniku przetwarzania strumienia Apache Flink, zapewnia wydajność i odporność, jakich wymagają aplikacje o krytycznym znaczeniu dla zespołu.
Cloudera Streams Messaging to solidna, skalowalna i bezpieczna architektura do przesyłania wiadomości dla aplikacji czasu rzeczywistego wykorzystujących platformę Apache Kafka. Zapewnia ona niezawodną warstwę transportu danych dla najbardziej wymagających obciążeń programistycznych.
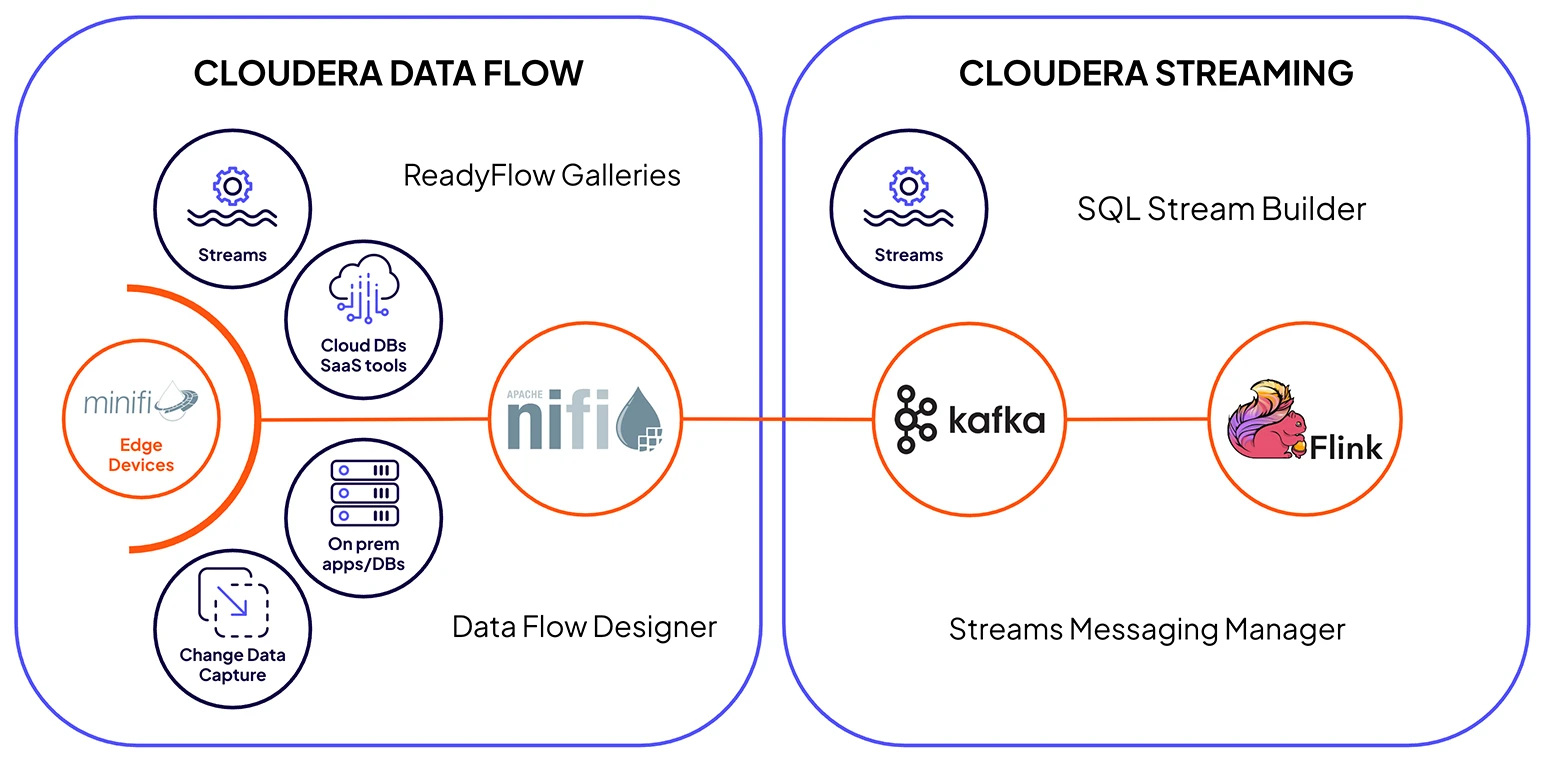
Cloudera Streaming w połączeniu z Cloudera Data Flow zapewnia zintegrowane komponenty klasy korporacyjnej, używając NiFi do bezpiecznego pozyskiwania, Kafka do odpornego przenoszenia i Flink do przetwarzania w czasie rzeczywistym w całym cyklu życia danych.
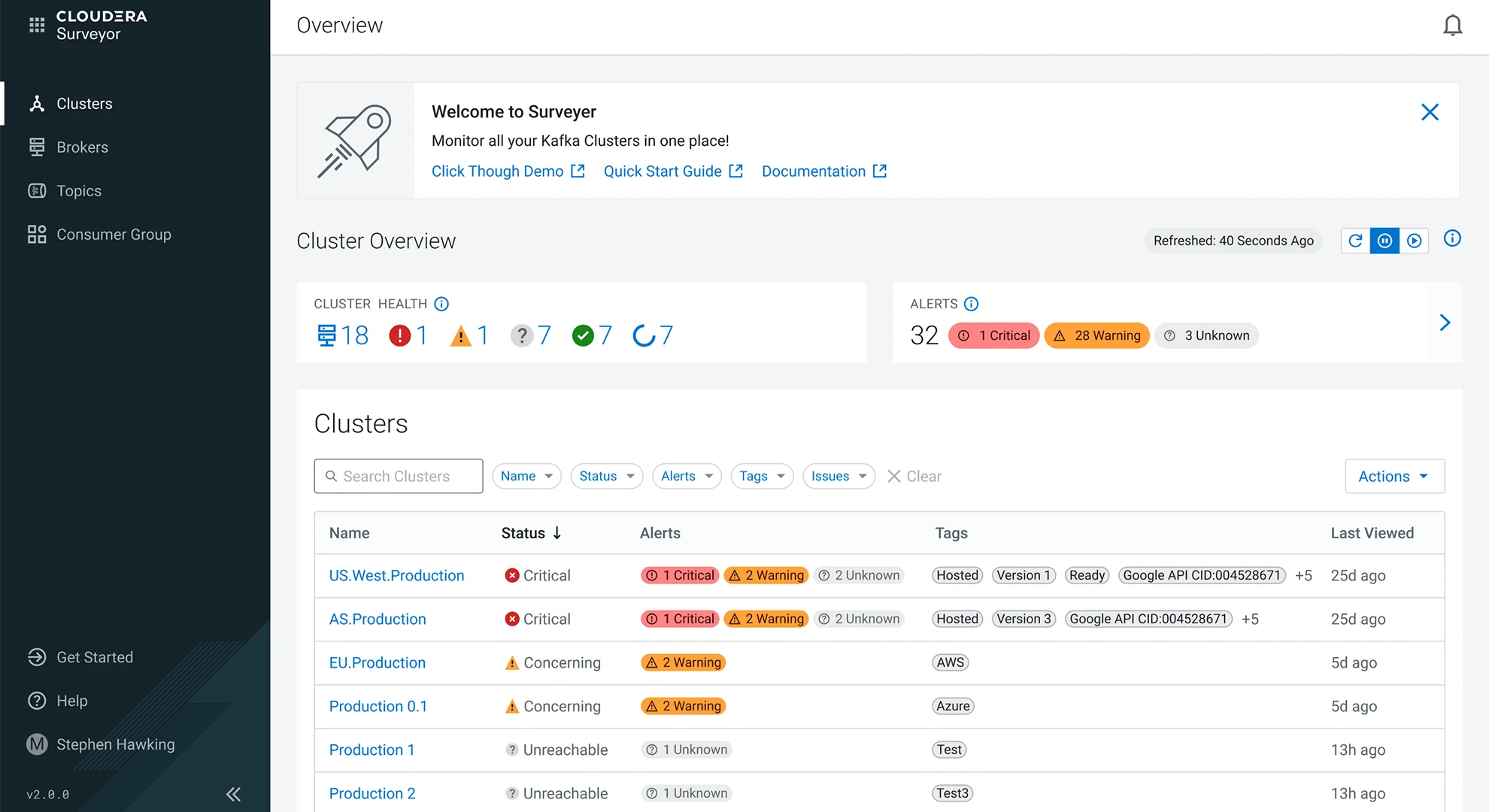
Cloudera Surveyor oferuje jeden interfejs dla obserwowalności Kafka na platformie Kubernetes, upraszczając operacje i zapewniając dobrą kondycję szkieletu danych aplikacji. Schema Registry udostępnia scentralizowane, wersjonowane repozytorium do zarządzania schematami danych.
Klienci
Cloudera Streaming generuje realną wartość w różnych branżach.
 Sektor publiczny
IRS
Sektor publiczny
IRS
 Usługi finansowe
Banco Santander Spain
Usługi finansowe
Banco Santander Spain
 Produkcja i motoryzacja
Dell
Produkcja i motoryzacja
Dell
Opcje wdrażania
Elastyczne fundamenty do tworzenia i wdrażania w dowolnym miejscu.
Dla aplikacji w chmurze publicznej
Pozwól swoim zespołom tworzyć i skalować aplikacje czasu rzeczywistego na ich wybranej platformie chmury publicznej.
W aplikacjach lokalnych
Wdrożenie w ramach chmury prywatnej zapewnia deweloperom maksymalną kontrolę nad opóźnieniami i zasobami.
Jako operator dla Kubernetes
Umożliw zespołowi DevOps niezależne oferowanie rozwiązań Flink i Kafka w zgodnym klastrze Kubernetes, aby zmaksymalizować elastyczność i samoobsługę.
Zrób następny krok
Zobacz, jak analizy w czasie rzeczywistym mogą odmienić organizację dzięki usłudze Cloudera Streaming.
Zapoznaj się z dokumentacją
Zapoznaj się z dokumentacją rozwiązania Cloudera Streaming Analytics działającego lokalnie, obsługiwanego przez Apache Flink.
Co nowego w Cloudera Streaming Analytics
Poznaj nowe funkcje poza podstawową funkcjonalnością Apache Flink i SQL Stream Builder.
Poznaj więcej produktów
Pozyskuj, przetwarzaj i analizuj w czasie rzeczywistym dane ustrukturyzowane i nieustrukturyzowane w każdym miejscu w celu uzyskiwania natychmiastowych analiz, podejmowania działań i wykorzystywania sztucznej inteligencji.
Analityki zasilane w czasie rzeczywistym poprzez gromadzenie, selekcjonowanie i analizowanie strumienia danych w ruchu z dowolnego źródła.
Podejmuj mądre decyzje dzięki elastycznej platformie, która przetwarza dowolne dane w każdym miejscu, w celu uzyskania przydatnych analiz i zaufanej sztucznej inteligencji.
Zarządzaj danymi z urządzeń krawędziowych, kontroluj je i monitoruj dzięki zbieraniu i przetwarzaniu danych na krawędzi w czasie rzeczywistym.
Przyspiesz proces podejmowania decyzji w oparciu o dane (od badań po produkcję) dzięki bezpiecznej, skalowalnej i otwartej platformie sztucznej inteligencji dla przedsiębiorstw.