Cloudera Data Warehouse
Analizuj ogromne ilości danych dla tysięcy jednoczesnych użytkowników i zarządzaj nimi bez kompromisów w zakresie kosztów, szybkości i bezpieczeństwa.

OGÓLNE INFORMACJE
Łatwo przekształcaj wszystkie dane w dowolnym miejscu w istotne statystyki biznesowe.
Natywne dla chmury, samoobsługowe środowisko analityczne, które przewyższa inne hurtownie danych o wszystkich rozmiarach i typach danych, jednocześnie zapewniając efektywne kosztowo skalowanie.
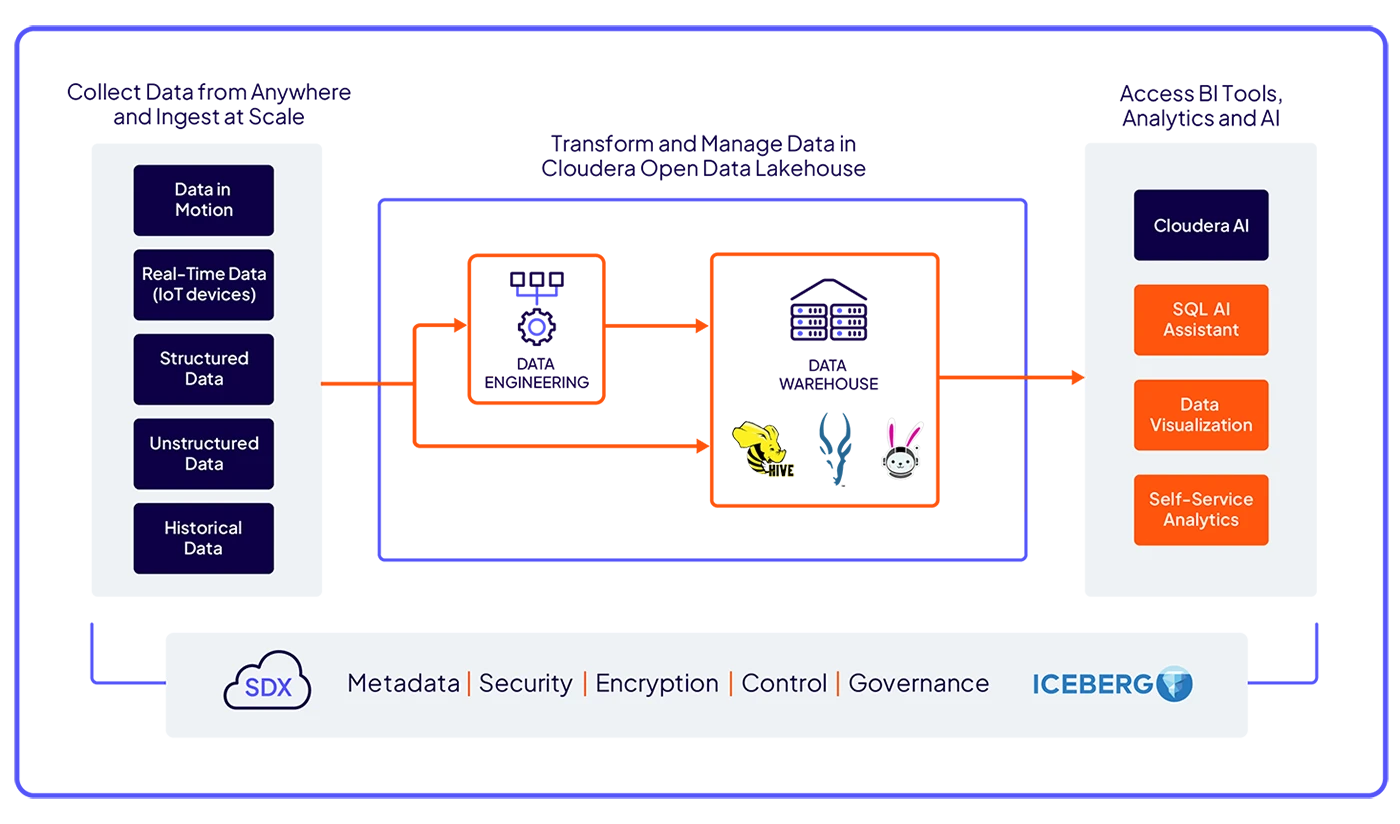
Odblokuj potężne analizy dzięki zaawansowanym silnikom SQL umożliwiającym szybkie przetwarzanie zapytań, inteligentne automatyzacje, SQL wspomagany sztuczną inteligencją oraz zoptymalizowaną wydajność obciążeń.
Pewnie i bezpiecznie twórz przepływy pracy analityki na ujednoliconej platformie opartej na Apache Iceberg, która zapewnia bezproblemowy dostęp do danych w każdym miejscu.
Zapewnij elastyczność obciążenia dzięki natywnym dla chmury silnikom typu open source oferującym pełną kontrolę nad danymi i brak uzależnienia od dostawcy.
PRZYKŁADY ZASTOSOWANIA
Używaj odpowiedniego silnika do właściwego obciążenia przy niższych kosztach.
-
Głębsze analizy dzięki zapytaniom federacyjnym i eksploracji ad hoc
Analizuj dane z różnych systemów za pomocą jednego zapytania SQL.
-
Ulepszone wsparcie podejmowania decyzji i business intelligence
Zapewnij samoobsługowy dostęp do dowolnych danych w każdym miejscu, szybko dostarczając krytycznych analiz.
-
Lepsza jakość danych dzięki potokom ETL i przetwarzaniu wsadowemu
Uzyskaj dostęp do elastycznej i szybkiej analityki na danych ustrukturyzowanych i nieustrukturyzowanych.
-
Analityka wielofunkcyjna z Apache Iceberg
Przekształcaj i przygotowuj duże ilości danych ustrukturyzowanych do analizy i raportowania na dalszych etapach.
-
Głębsze analizy dzięki zapytaniom federacyjnym i eksploracji ad hoc
Analizuj dane z różnych systemów za pomocą jednego zapytania SQL.
-
Ulepszone wsparcie podejmowania decyzji i business intelligence
Zapewnij samoobsługowy dostęp do dowolnych danych w każdym miejscu, szybko dostarczając krytycznych analiz.
-
Lepsza jakość danych dzięki potokom ETL i przetwarzaniu wsadowemu
Uzyskaj dostęp do elastycznej i szybkiej analityki na danych ustrukturyzowanych i nieustrukturyzowanych.
-
Analityka wielofunkcyjna z Apache Iceberg
Przekształcaj i przygotowuj duże ilości danych ustrukturyzowanych do analizy i raportowania na dalszych etapach.
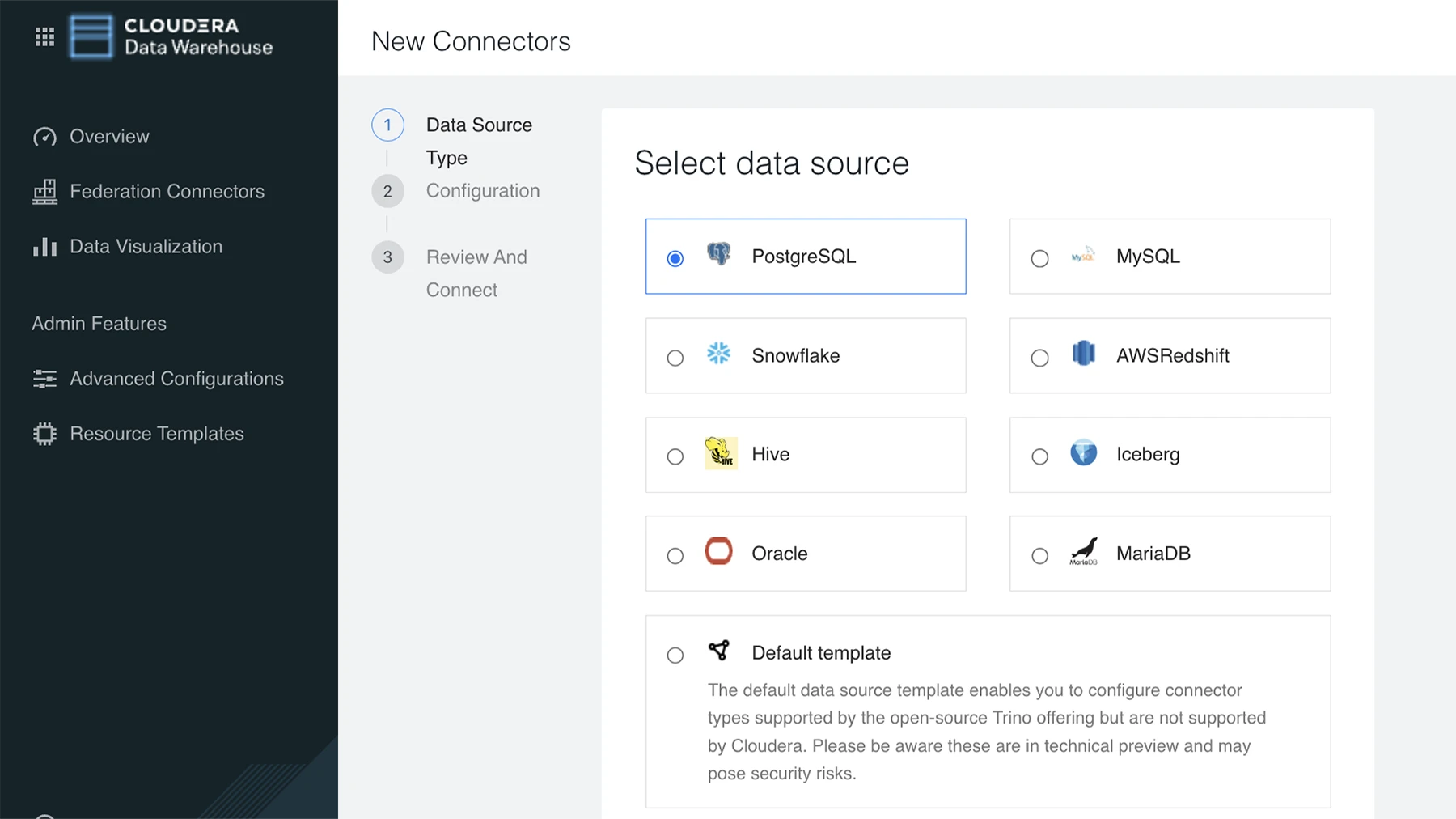
Udostępnij analitykom danych i naukowcom możliwość wykonywania zapytań na ogromnych zbiorach danych analitycznych z różnych źródeł.
Analizuj dane z różnych źródeł bez konieczności przeprowadzania migracji danych lub złożonej integracji.

Zapewnij użytkownikom samoobsługowy dostęp do danych zdarzeń i szeregów czasowych o niskim opóźnieniu.
Twórz interaktywne raporty i pulpity nawigacyjne, które wykorzystują dane w czasie rzeczywistym na dużą skalę i umożliwiają szybkie wykonywanie zapytań.
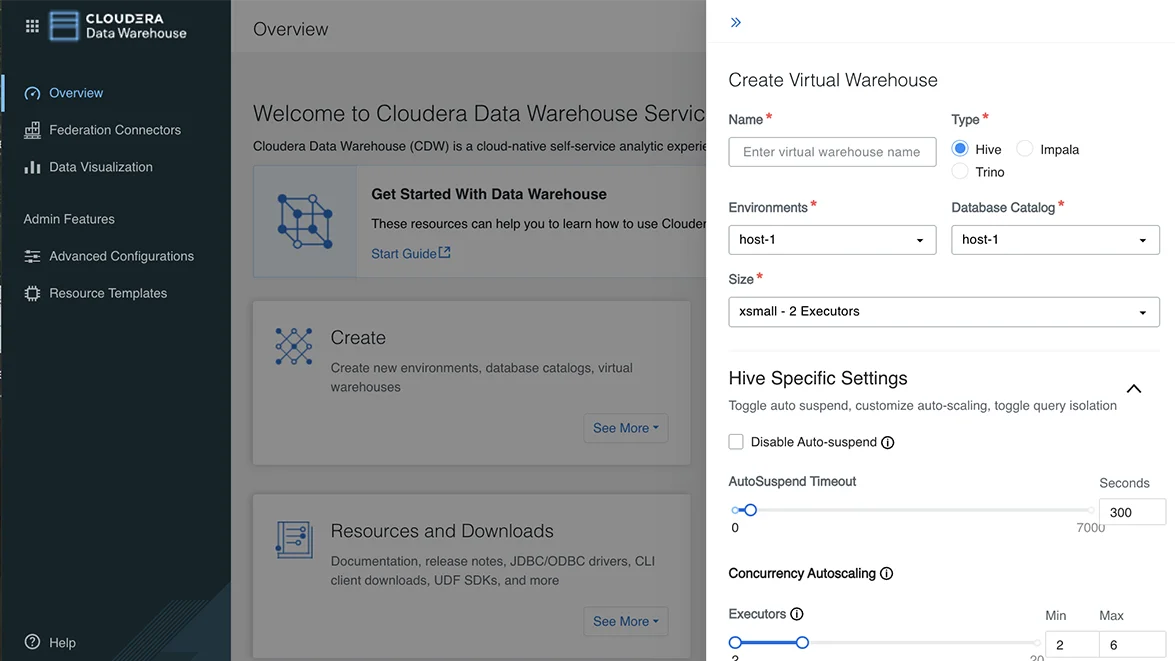
Wykonuj złożone zapytania na ogromnych zbiorach danych i zaplanowanych zadaniach o dużym wolumenie.
Obsługuj transformację i przygotowywanie dużych ilości danych ustrukturyzowanych do analizy i raportowania na dalszych etapach.

Zapewnij użytkownikom możliwość korzystania z preferowanych narzędzi do analizy danych.
Osiągnij płynną interoperacyjność z silnikami innych firm i ujednolić dane w całej organizacji, sprzyjając lepszej współpracy.
Pełni funkcję eksperta w danej dziedzinie i przewodnika SQL: użytkownicy opisują potrzeby dotyczące danych w języku naturalnym, a asystent wyszukuje odpowiednie dane, zapisuje je, optymalizuje i wyjaśnia zapytanie w łatwych do zrozumienia terminach.
Zapewnia wbudowane funkcje od sztucznej inteligencji do BI oraz płynne, gotowe wizualizacje w ramach narzędzia Cloudera Data Visualization. Twórz interaktywne pulpity nawigacyjne i natychmiast udostępniaj analizy w całej firmie.
Maksymalizuje wykonywanie mieszanych obciążeń w ramach jednej wirtualnej hurtowni. Takie podejście oferuje najlepszą cenę za wydajność, zapewniając płynne, niedrogie i opłacalne wykonywanie operacji związanych z danymi.
Obsługuje szeroki wachlarz obciążeń i typów danych, w tym dane ustrukturyzowane i nieustrukturyzowane. Ta wszechstronność obejmuje wszelkie wymagania dotyczące obciążenia: zaawansowaną analitykę, raportowanie na pulpicie nawigacyjnym lub przetwarzanie w czasie rzeczywistym.
Integruje środowiska lokalne i chmurowe z wbudowanym ujednoliconym bezpieczeństwem i zarządzaniem. Funkcje hybrydowe, dostęp do danych, przenośność i skalowalność umożliwiają silnikom bezpieczne odczytywanie i zapisywanie danych w różnych formatach.
Klienci
Klienci rozwijają się i wprowadzają innowacje dzięki rozwiązaniu Cloudera Data Warehouse.
Inwestycja w Cloudera pozwoliła Axis Bank w pełni wykorzystać jego dane, co pobudziło innowacyjność, wydajność i znacznie poprawiło zdolność banku do zapewniania wyjątkowej obsługi klienta.
 Ochrona zdrowia
IQVIA
Ochrona zdrowia
IQVIA
 Produkcja i motoryzacja
International
Produkcja i motoryzacja
International
 Transport
GEODIS
Transport
GEODIS
Migracja do Apache® Iceberg dla początkujących
Zachęcamy do przeczytania planu krok po kroku dotyczącego migracji zadań do Apache Iceberg.

{kind=link}
Zrób następny krok
Chcesz zobaczyć Cloudera Data Warehouse w działaniu? Lub uzyskać z pierwszej ręki informacje o naszych najnowszych aktualizacjach produktów? To proste.
Zapoznaj się z dokumentacją
Szczegółowe informacje techniczne, przewodniki szybkiego startu i informacje na temat poszczególnych wersji usług Cloudera Data Warehouse.
Dołącz do społeczności
Pozostań w kontakcie i na bieżąco, dołączając do społeczności Cloudera.
Poznaj więcej produktów
Otwarta architektura Data Lakehouse
Podejmuj mądre decyzje dzięki elastycznej platformie, która przetwarza dowolne dane w każdym miejscu, w celu uzyskania przydatnych analiz i zaufanej sztucznej inteligencji.
Wykorzystaj moc AI w Twojej firmie, bezpiecznie i na dowolną skalę, przy zapewnieniu możliwości identyfikacji analiz oraz ich wyjaśniania i zastosowaniu mechanizmów zaufania.
Cloudera Data Science & Engineering
Bezpiecznie buduj, organizuj i nadzoruj potoki danych klasy korporacyjnej z Apache Spark na platformie Iceberg.
Przyspiesz proces podejmowania decyzji w oparciu o dane (od badań po produkcję) dzięki bezpiecznej, skalowalnej i otwartej platformie sztucznej inteligencji dla przedsiębiorstw.
Umożliwiaj użytkownikom biznesowym szybkie i łatwe eksplorowanie zarządzanych danych, współpracę i odblokowywanie analiz za pomocą pulpitów nawigacyjnych opartych na sztucznej inteligencji.