Cloudera AI Inference Service
Przyspiesz obsługę modeli, aby wdrażać i skalować prywatne aplikacje AI, agentów i asystentów z niezrównaną szybkością, zabezpieczeniami i efektywnością.

Rozwijaj i wdrażaj rozwiązania AI, zabezpieczając jednocześnie wszystkie etapy cyklu życia sztucznej inteligencji.
Obsługiwana przez mikrousługi NVIDIA NIM usługa Cloudera AI Inference Service zapewnia czołową na rynku wydajność — oferując do 36 razy szybsze wnioskowanie na procesorach GPU firmy NVIDIA i prawie 4 razy większą przepustowość na procesorach CPU — co usprawnia zarządzanie sztuczną inteligencją i zapewnia płynny nadzór w chmurach publicznych i prywatnych.
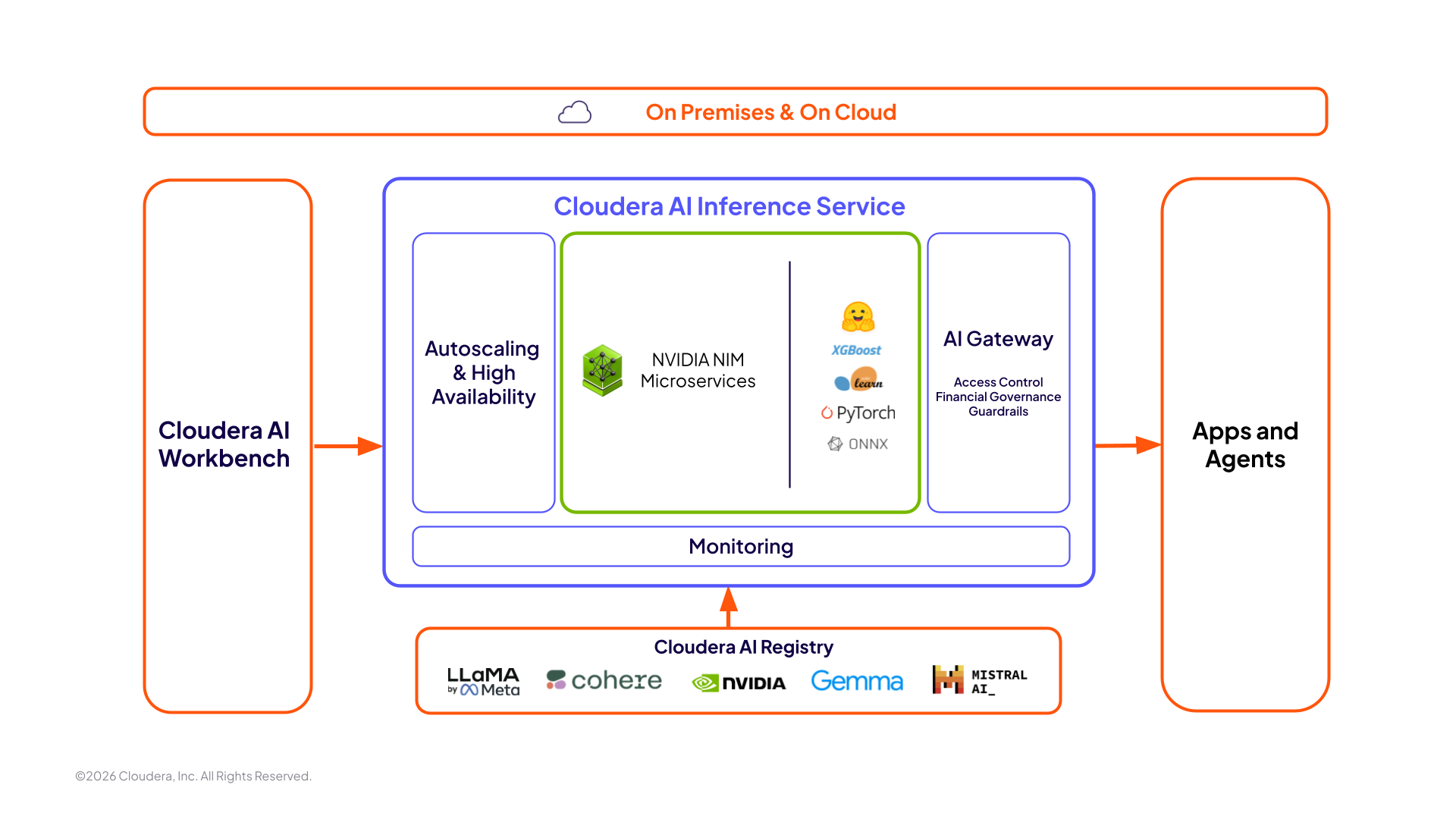
Jedna usługa dla wszystkich potrzeb przedsiębiorstwa w zakresie wnioskowania AI
Wdrożenie jednym kliknięciem: szybkie przejście modelu od rozwoju do produkcji niezależnie od środowiska.
Jedno zabezpieczone środowisko: niezawodne i kompleksowe zabezpieczenia obejmujące wszystkie etapy cyklu życia AI.
Jedna platforma: bezproblemowe zarządzanie wszystkimi modelami za pomocą jednej platformy, która zaspokaja wszystkie potrzeby związane ze sztuczną inteligencją.
Kompleksowe wsparcie: ujednolicone wsparcie firmy Cloudera w zakresie wszystkich pytań dotyczących sprzętu i oprogramowania.
Kluczowe cechy usługi inferencji AI
Opcje wdrażania usługi AI Inference
Uruchamiaj obciążenia wnioskowania lokalnie lub w chmurze bez uszczerbku dla wydajności, bezpieczeństwa lub kontroli.
Cloudera w chmurze
- Elastyczność w zakresie wielu chmur: wdrażaj w chmurach publicznych, unikaj uzależnienia od jednego ekosystemu.
- Szybsze osiąganie wartości: rozpocznij wnioskowanie bez konfigurowania infrastruktury — idealne do szybkich eksperymentów.
- Elastyczna skalowalność: obsługuj nieprzewidywalny ruch dzięki automatycznemu skalowaniu do zera i mikrousługom zoptymalizowanym pod kątem GPU.
Cloudera w środowisku lokalnym
- Suwerenność danych: zachowaj pełną kontrolę. Utrzymuj modele, polecenia i zasoby całkowicie za zaporą ogniową.
- Gotowe do hermetyzacji: przeznaczony dla środowisk regulowanych, takich jak administracja rządowa, opieka zdrowotna i usługi finansowe.
- Przewidywalny i niższy całkowity koszt posiadania: wyeliminuj niespodzianki dzięki stałym cenom i niższemu całkowitemu kosztowi posiadania w porównaniu z interfejsami API w chmurze opartymi na tokenach.
DEMO
Sprawdź, jak działa bezproblemowe wdrażanie modelu
Zobacz, jak łatwo można wdrażać duże modele językowe za pomocą zaawansowanych narzędzi Cloudera, aby skutecznie zarządzać wielkoskalowymi aplikacjami AI.

Integracja z rejestrem modeli:
bezproblemowo uzyskuj dostęp, przechowuj i wersjonuj modele oraz zarządzaj nimi za pośrednictwem scentralizowanego repozytorium Cloudera AI Registry.
Łatwa konfiguracja i wdrożenie: wdrażaj modele w środowiskach chmurowych, konfiguruj punkty końcowe i dostosowuj automatyczne skalowanie w celu uzyskania najlepszej skuteczności.
Monitorowanie wydajności:
rozwiązuj problemy i optymalizuj na podstawie kluczowych wskaźników, takich jak opóźnienie, przepustowość, wykorzystanie zasobów i kondycja modelu.

Usługa Cloudera AI Inference pozwala odblokować pełny potencjał danych na dużą skalę dzięki specjalistycznej wiedzy firmy NVIDIA w zakresie sztucznej inteligencji, a także zapewnić im bezpieczeństwo za pomocą funkcji zabezpieczeń klasy korporacyjnej, dzięki czemu można pewnie chronić dane i uruchamiać obciążenia w środowisku lokalnym lub w chmurze, jednocześnie efektywnie wdrażając modele AI z niezbędną elastycznością i nadzorem.
Zaangażuj się
Zrób następny krok
Poznaj zaawansowane możliwości i zanurz się w szczegóły dzięki zasobom i przewodnikom, które pomogą szybko rozpocząć pracę.
Prezentacja produktu usługi AI Inference
Poznaj od środka usługę Cloudera AI Inference.
Dokumentacja usługi AI Inference
Znajdź wszystko, od opisów funkcji po przydatne przewodniki wdrażania.
Poznaj więcej produktów
Przyspiesz proces podejmowania decyzji w oparciu o dane (od badań po produkcję) dzięki bezpiecznej, skalowalnej i otwartej platformie sztucznej inteligencji dla przedsiębiorstw.
Odblokuj przepływy pracy prywatnej generatywnej AI i agentów na każdym poziomie umiejętności dzięki szybkości rozwiązania low-code i pełnej kontroli nad kodem.
Wykorzystaj moc AI w Twojej firmie, bezpiecznie i na dowolną skalę, przy zapewnieniu możliwości identyfikacji analiz oraz ich wyjaśniania i zastosowaniu mechanizmów zaufania.
Poznaj kompleksową platformę do szybkiego tworzenia, wdrażania i monitorowania gotowych do wykorzystania aplikacji ML.