
Strategie wzrostu nieorganicznego, takie jak fuzje i przejęcia (M&A), służą jako strategiczne dźwignie wzrostu, umożliwiając firmom realizację synergii przychodów i kosztów lub szybkie nabywanie nowych zdolności, które zapewnią długoterminową przewagę konkurencyjną. Na przykład obecnie obserwujemy, jak duże organizacje nabywają mniejsze, innowacyjne start-upy AI, aby przyspieszyć swoje działania na rzecz transformacji z zastosowaniem sztucznej inteligencji i uzyskać przewagę konkurencyjną.
Integracja technologii odgrywa kluczową rolę w przechwytywaniu wartości z fuzji i przejęć. Badanie Deloitte dowodzi, że IT jest kluczowym czynnikiem napędzającym korzyści z integracji, odpowiadając za ponad 50% wszystkich synergii. Jednak ze względu na rozprzestrzenianie się silosów danych oraz zróżnicowanych architektur i środowisk technologicznych, organizacje stoją przed kilkoma wyzwaniami związanymi z danymi po fuzji w ramach realizowania korzyści z integracji technologii.
W tym artykule przedstawiono pięcioetapowe ramy pozwalające sprostać tym wyzwaniom i przyspieszyć osiąganie wartości w kontekście fuzji i przejęć. Te ramy zapewnią, że strategia danych po fuzji z Cloudera dostarczy możliwości potrzebnych do usprawnienia procesu integracji technologii.
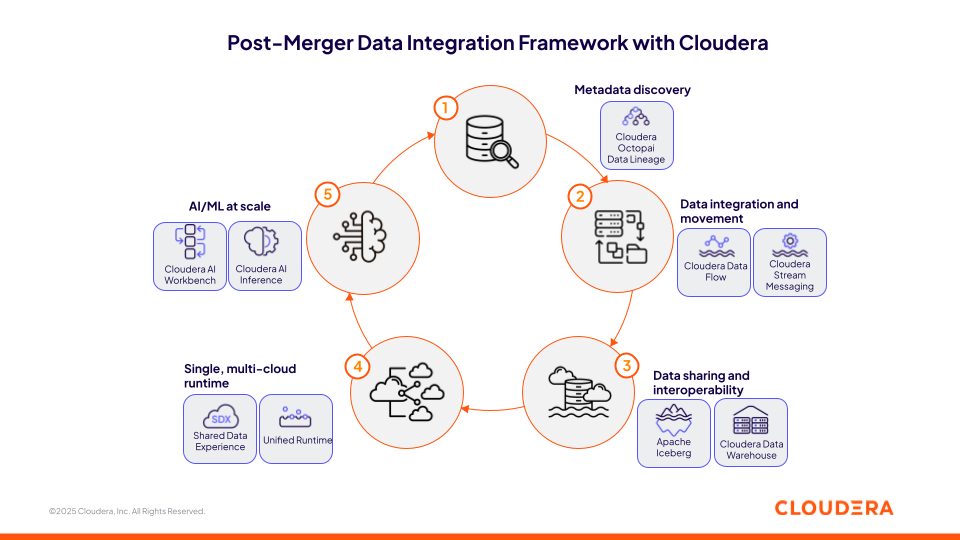
Rysunek 1. Struktura integracji danych po fuzji z Cloudera
1. Przyspieszanie integracji po fuzji dzięki Cloudera Octopai Data Lineage
Na początku integracji po fuzji faza odnajdywania danych często staje się wąskim gardłem, ponieważ pofragmentowane i nieudokumentowane źródła opóźniają krytyczne analizy i działania w celu zapewnienia zgodności z przepisami. Cloudera Octopai Data Lineage stawia czoła temu wyzwaniu, oferując zautomatyzowane rozwiązanie do zarządzania metadanymi oparte na sztucznej inteligencji, które przyspiesza odnajdywanie danych, kompleksowe ustalanie pochodzenia danych i katalogowanie w złożonych środowiskach hybrydowych i wielochmurowych.
Cloudera Octopai Data Lineage skutecznie mapuje przepływy danych i wypełnia luki w metadanych, dostarczając wielowymiarowych informacji o pochodzeniu danych, które śledzi pochodzenie i transformacje w celu zapewnienia pełnej przejrzystości. Ponad 60 natywnych integracji i uniwersalnych łączników dla systemów innych niż natywne sprawia, że Cloudera Octopai Data Lineage usprawnia wdrażanie nabytych zasobów danych, poprawiając tym samym przejrzystość, jakość i zaufanie do danych.
Na przykład w scenariuszach fuzji bankowych ta funkcja ułatwia szybkie identyfikowanie i tagowanie zbiorów danych związanych z ryzykiem, zapewniając zgodność z normami regulacyjnymi, takimi jak BCBS 239, przy jednoczesnym minimalizowaniu zapotrzebowania na rozległe ręczne audyty lub interwencje.
2. Integrowanie różnych źródeł danych dzięki danym w ruchu Cloudera
Integracja zróżnicowanych źródeł danych i eliminowanie złożonych, niestandardowych potoków ETL jest krytycznym wyzwaniem po fuzji. Cloudera dostarcza niezawodnych możliwości wsadowego pozyskiwania, przetwarzania i rozpowszechniania danych w czasie rzeczywistym za pośrednictwem rozwiązania Cloudera Data Flow (obsługiwanego przez Apache NiFi) i Cloudera Streaming (obsługiwanego przez Apache Kafka i Apache Flink).
Ponad 450 łączników sprawia, że Cloudera Data Flow zapewnia wizualny interfejs typu przeciągnij i upuść do pozyskiwania danych z różnorodnych, heterogenicznych źródeł danych, zarówno lokalnych, w chmurze, jak i na krawędzi sieci. Dodatkowo rozwiązanie Cloudera Streaming udostępnia architekturę magistrali komunikacyjnej, która rozdziela systemy źródłowe od systemów odbiorczych między te dwa podmioty, co eliminuje integracje między punktami zwiększające złożoność architektoniczną i koszty.
Podczas integracji po fuzji te funkcje mogą znacznie przyspieszyć i uprościć przenoszenie danych między organizacjami. Na przykład rozwiązanie Cloudera Data Flow może być używane do szybkiego integrowania lokalnych danych ze starszych systemów źródłowych firmy przejętej z natywną dla chmury hurtownią danych firmy nadrzędnej, przyspieszając proces podejmowania decyzji.
3. Budowanie bezpiecznej warstwy udostępniania danych w otwartej architekturze Data Lakehouse Cloudera z Apache Iceberg
Udostępnianie danych między łączącymi się podmiotami jest niezbędnym wymogiem do zintegrowanego podejmowania decyzji i uzyskiwania analiz. Ten proces może być złożony ze względu na różnorodne technologie analityki eksploracyjnej i business intelligence, a także odmienne modele bezpieczeństwa danych stosowane przez różne systemy.
Podejście otwartej architektury data lakehouse, które łączy Apache Iceberg, Cloudera Iceberg REST Catalog oraz Cloudera Shared Data Experience (SDX), umożliwia organizacjom tworzenie ujednoliconej warstwy udostępniania danych. Ta warstwa jest zgodna z różnymi silnikami analitycznymi (takimi jak Snowflake, Databricks, AWS EMR, AWS Athena i Salesforce Data Cloud, pod warunkiem że te silniki obsługują Iceberg REST Catalog) i zapewnia szczegółowy model bezpieczeństwa oraz zarządzania w celu zarządzania dostępem dla zróżnicowanej grupy użytkowników, w tym nowo zintegrowanych zespołów zajmujących się Data Science.
Na przykład dwie organizacje opieki zdrowotnej produkujące leki mogą wykorzystać Cloudera do zbudowania architektury data lakehouse zgodnej z GxP, która konsoliduje zasoby danych łączących się podmiotów, jednocześnie zapewniając przestrzeganie wymogów regulacyjnych.
4. Standaryzowanie inicjatyw międzyśrodowiskowych w jednym środowisku wielochmurowym
Różne środowiska stosowane do działań analitycznych w dwóch łączących się podmiotach prowadzą do powielania operacji w całym cyklu życia danych, w tym wielu potoków inżynierii danych dla typowych zadań, takich jak pozyskiwanie danych i ich standaryzacja.
Cloudera umożliwia organizacjom standaryzację danych i operacji AI we wspólnym środowisku wykonawczym w różnych środowiskach chmury prywatnej i publicznej. Ta możliwość wynika z podstawowego, skonteneryzowanego modelu infrastruktury stosowanego w różnych środowiskach, spójnego mechanizmu uwierzytelniania i autoryzacji użytkowników (Cloudera SDX) oraz narzędzia Cloudera Manager, które służy jako pojedynczy interfejs do zarządzania klastrami w różnych regionach i środowiskach wdrożeniowych.
W kontekście po fuzji ta standaryzacja ma charakter transformacyjny: obie firmy mogą zintegrować swoje operacje cyklu życia danych w jednym środowisku wykonawczym, eliminując nadmiarowe narzędzia i ułatwiając udostępnianie danych, analiz oraz modeli sztucznej inteligencji. Prowadzi to do obniżenia kosztów technologii i pracy w operacjach na danych oraz opracowywaniu modeli AI/ML, zwiększenia produktywności specjalistów, konsolidacji wielu narzędzi i redukcji silosów danych.
5. Skalowanie inicjatyw AI w dowolnym miejscu dzięki Cloudera AI
Po przejęciu lub fuzji najpilniejszym wyzwaniem jest integracja zróżnicowanych narzędzi, modeli i analityków danych z nowo nabytego innowacyjnego start-upu przy jednoczesnym zarządzaniu zmieniającymi się wymaganiami dotyczącymi zdolności produkcyjnych. Cloudera AI Workbench i AI Inference umożliwiają organizacjom skalowanie inicjatyw AI lokalnie lub w chmurze poprzez:
Dostarczanie kompleksowego, opartego na kontenerach rozwiązania do inżynierii funkcji, szkolenia modeli, śledzenia eksperymentów i wdrażania modeli
Ułatwianie udostępniania modeli sztucznej inteligencji, które pozwala analitykom danych współpracować między różnymi zespołami
Wykorzystanie usług przyspieszania sprzętowego i programowego od partnerów Cloudera, które mogą przyspieszyć cały cykl życia data science poprzez 20-krotną poprawę wydajności inżynierii danych i nawet 6-krotne zwiększenie wydajności wnioskowania AI
Dzięki Cloudera zintegrowana firma może osiągnąć znaczne obniżenie kosztów poprzez przenoszenie trwałych, wymagających dużych obliczeń obciążeń, takich jak udostępnianie modelu AI/ML, do środowisk lokalnych. Co ważniejsze, może skrócić czas wprowadzania na rynek nowych, połączonych aplikacji AI. Pozwala to organizacji szybko zrealizować „przewagę konkurencyjną”, której w pierwszej kolejności oczekiwała w wyniku fuzji i przejęć.
Podejmowanie kolejnych kroków w celu zapewnienia pomyślnej integracji po kolejnej fuzji i przejęciu
Cloudera może przyspieszyć integrację zasobów danych i możliwości analitycznych po fuzji między dwoma integrującymi się podmiotami. Nasza platforma oferuje skalowalność w całym cyklu życia danych, model wdrażania niezależny od infrastruktury oraz interoperacyjność architektury data lakehouse w usługach Cloudera i Apache Iceberg. To połączenie zapewnia architektoniczny schemat standaryzacji inicjatyw AI/ML i operacji związanych z danymi oraz dostarczania modelu udostępniania danych, który może być używany zarówno przez usługi firmy Cloudera, jak i usługi firm innych niż Cloudera.
Aby zaplanować demonstrację lub prezentację produktu, skontaktuj się z naszym zespołem.
