Badania Fast Forward Labs są teraz dostępne bez subskrypcji
W przyszłości wszystkie nowe raporty będą dostępne publicznie i będzie je można pobrać bezpłatnie. Wkrótce udostępnimy także zaktualizowane wersje starszych raportów, więc zachęcamy do częstego sprawdzania i eksploracji nowej zawartości.
Bezpłatne raporty z badań
Poznaj nasze najnowsze raporty z badań i prototypy — dostępne bezpłatnie dla wszystkich.
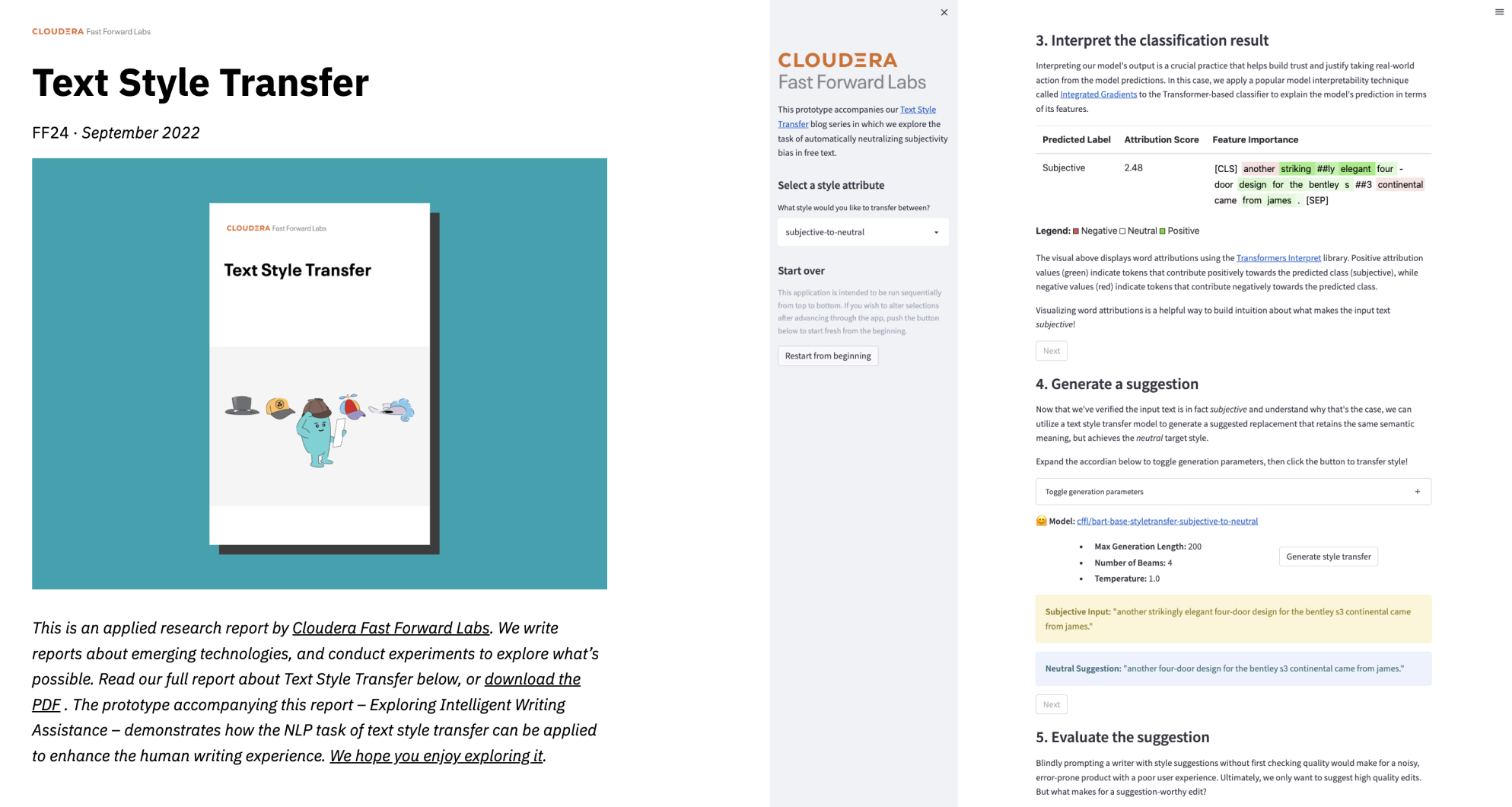
Transfer stylu tekstu (TST)
Zadanie NLP polegające na transferze stylu tekstu (TST) ma na celu automatyczną kontrolę atrybutów stylu fragmentu tekstu przy jednoczesnym zachowaniu jego treści, co znacząco wpływa na użyteczność NLP dla użytkownika. W raporcie omówiono technikę transferu stylu tekstu neutralizującą subiektywność w swobodnym tekście. Opisano również podejście do modelowania sekwencji z wykorzystaniem transformatorów HuggingFace i przedstawiono zestaw niestandardowych, pozbawionych odniesień metryk oceny służących określeniu wydajności modelu. W końcowej części artykułu omówiono zagadnienia etyczne dotyczące naszego prototypu narzędzia do inteligentnego wspomagania pisania.
Wnioskowanie dryfu pojęć bez oznaczonych danych
Dryf pojęć występuje, gdy właściwości statystyczne domeny docelowej zmieniają się w czasie, powodując pogorszenie wydajności modelu. Wykrywanie dryfu jest zazwyczaj osiągane przez monitorowanie metryki wydajności i wyzwalanie potoku ponownego trenowania, gdy metryka spadnie poniżej określonego progu. Podejście to zakłada jednak, że w czasie przewidywania dostępna jest wystarczająca ilość oznaczonych danych, co dla wielu systemów produkcyjnych jest nierealistycznym ograniczeniem. W tym raporcie badamy różne podejścia do radzenia sobie z dryfem pojęć, gdy oznaczone dane nie są łatwo dostępne.

Wielokryterialna optymalizacja hiperparametrów
Opracowujemy modele uczenia maszynowego na bazie „typowych” metryk, takich jak dokładność predykcyjna, przypominanie i precyzja. Jednak te metryki rzadko są naprawdę wszystkim, na czym nam zależy. Modele produkcyjne muszą również spełniać wymagania fizyczne, takie jak ograniczenia dotyczące opóźnień, zużycia pamięci i bezstronności. Optymalizacja hiperparametrów staje się jeszcze trudniejsza, gdy trzeba zoptymalizować wiele metryk. Nasze najnowsze badanie szczegółowo analizuje ten scenariusz „wielokryterialnej” optymalizacji hiperparametrów.

Uczenie głębokie do automatycznej weryfikacji podpisów offline
Weryfikacja podpisu odręcznego służy do automatycznego rozróżniania między podpisami autentycznymi a podrobionymi i jest szczególnie ważnym wyzwaniem ze względu na wszechobecność podpisów odręcznych jako formy identyfikacji w obszarach prawa, finansów i administracji. W ramach tego cyklu badań analizowano zastosowanie metod uczenia głębokiego metryk – w szczególności sieci syjamskich – w połączeniu z nowatorskimi metodami ekstrakcji cech w celu ulepszenia tradycyjnych technik.

Systemy rekomendacji oparte na sesji
Systemy rekomendacji stały się kamieniem węgielnym współczesnego życia. Są wszechobecne w sektorach obejmujących handel internetowy, przesyłanie strumieniowe muzyki i wideo, a nawet publikowanie treści. Systemy te pomagają nam poruszać się po ogromnej ilości treści w Internecie, pozwalając nam odkrywać interesujące lub ważne dla nas materiały. Kluczowym trendem w ciągu ostatnich kilku lat są algorytmy rekomendacji oparte na sesji, które dostarczają rekomendacje wyłącznie na podstawie interakcji użytkownika w trwającej sesji i nie wymagają istnienia profilów użytkowników ani żadnych ich historycznych preferencji.

Klasyfikacja tekstu w kilku ujęciach
Klasyfikacja tekstu może służyć do analizy opinii, przypisywania tematów, identyfikacji dokumentów, rekomendacji artykułów i nie tylko. Chociaż obecnie istnieją dziesiątki technik wykonywania tego podstawowego zadania, wiele z nich wymaga ogromnych ilości oznaczonych danych, aby były użyteczne. Zbieranie uwag do danego przypadku jest zwykle jedną z najbardziej kosztownych części każdego zastosowania uczenia maszynowego. W tym raporcie zgłębiamy zagadnienie wykorzystania ukrytego osadzania tekstu z kilkoma przykładami szkoleniowymi (lub nawet ich brakiem) i przedstawiamy najlepsze praktyki wdrażania tej metody.

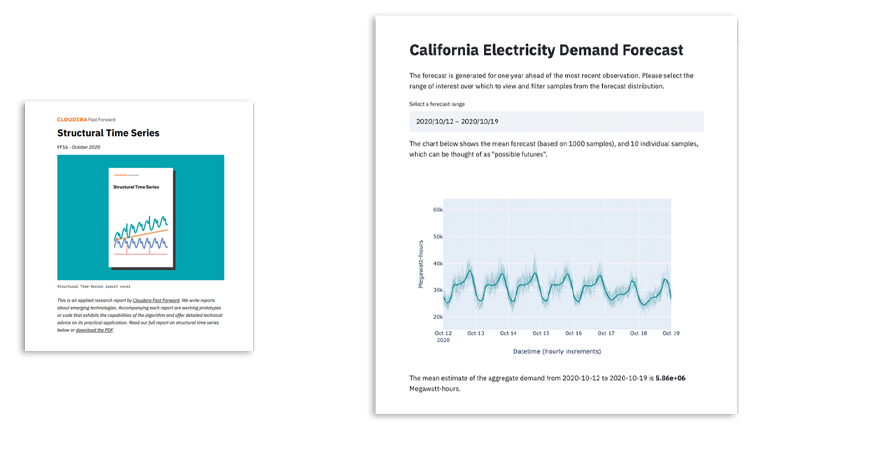
Strukturalne szeregi czasowe
Dane w postaci szeregów czasowych są wszechobecne. Niniejszy raport analizuje uogólnione modele addytywne, które pozwalają w prosty, elastyczne i interpretowalny sposób modelować szeregi czasowe poprzez rozkładanie ich na komponenty strukturalne. Przyglądamy się korzyściom i kompromisom wynikającym z zastosowania podejścia dopasowującego krzywą do szeregów czasowych i demonstrujemy jego wykorzystanie za pośrednictwem biblioteki Prophet Facebooka w przypadku problemu z prognozowaniem popytu.
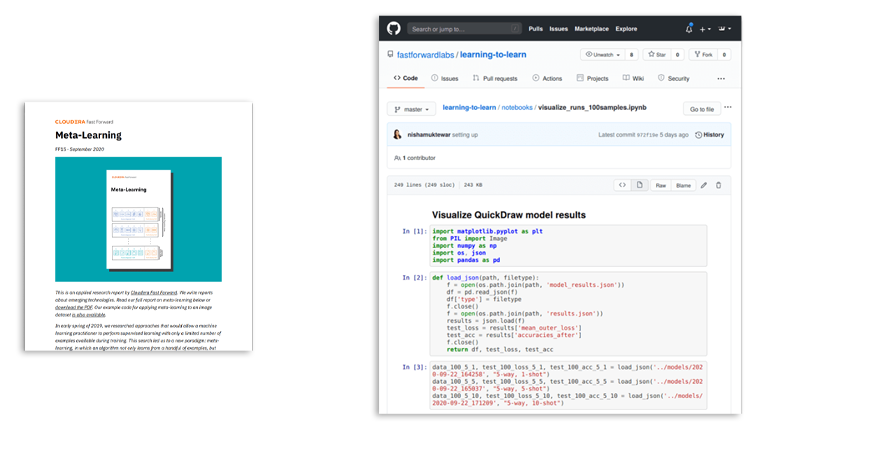
Meta-learning
W przeciwieństwie do tego, jak uczą się ludzie, algorytmy uczenia głębokiego potrzebują ogromnych ilości danych i możliwości obliczeniowych, a mimo to mogą mieć trudności z generalizacją. Ludzie potrafią się szybko przystosowywać, ponieważ w obliczu nowych problemów wykorzystują wiedzę zdobytą dzięki wcześniejszym doświadczeniom. W tym raporcie wyjaśniamy, w jaki sposób meta-learning może wykorzystać wcześniejszą wiedzę uzyskaną na podstawie danych, aby szybko i wydajniej rozwiązywać nowe zadania w czasie testów
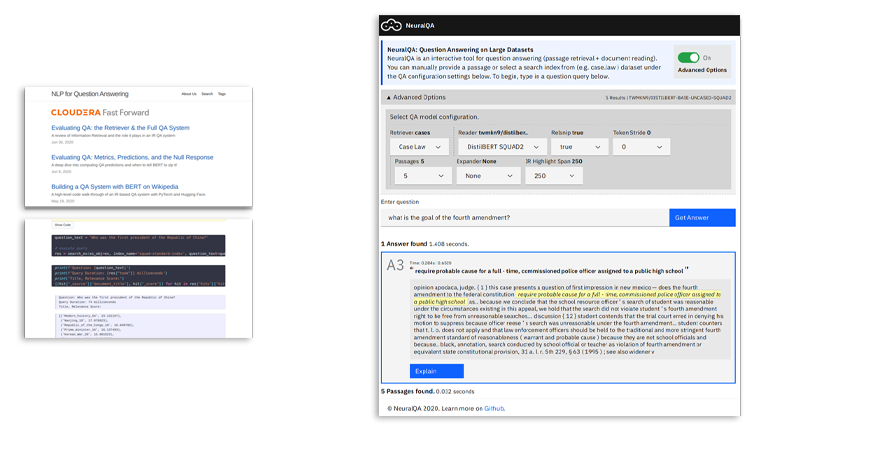
Automatyczne odpowiadanie na pytania
Automatyczne odpowiadanie na pytania to łatwy w obsłudze sposób wydobywania informacji z danych przy użyciu naturalnego języka. Dzięki niedawnym postępom w przetwarzaniu języka naturalnego możliwości odpowiadania na pytania z nieustrukturyzowanych danych tekstowych gwałtownie wzrosły. Niniejszy blog zawiera omówienie szczegółów technicznych i praktycznych aspektów tworzenia kompleksowego systemu odpowiadania na pytania.
Przyczynowość w uczeniu maszynowym
Zależność wnioskowania przyczynowego i uczenia maszynowego to szybko rozwijający się obszar badań, który już dostarcza możliwości tworzenia solidniejszych, bardziej niezawodnych i sprawiedliwych systemów uczenia maszynowego. Niniejszy raport zawiera wprowadzenie do rozumowania przyczynowego, w tym do wykresów przyczynowych i predykcji niezmienników, a także stosowania narzędzi wnioskowania przyczynowego w połączeniu z klasycznymi technikami uczenia maszynowego w wielu przypadkach użycia.

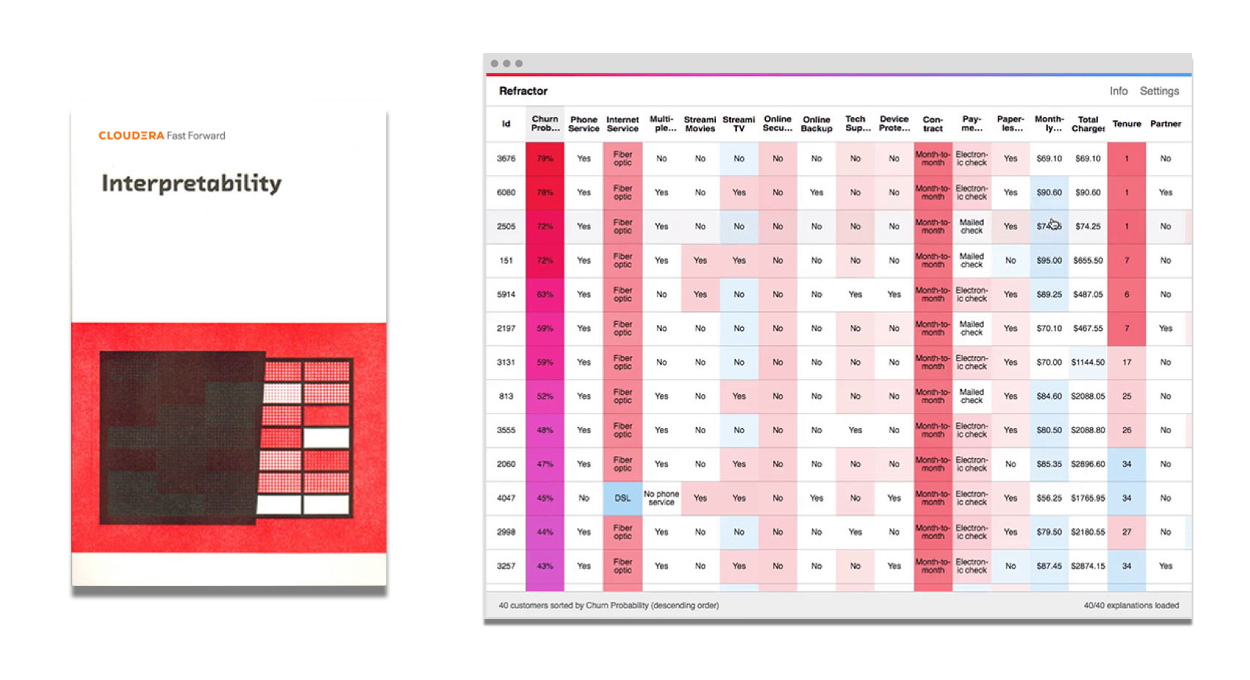
Możliwości interpretacji: edycja 2020
Możliwość interpretacji lub wyjaśnienia, dlaczego i jak system podejmuje decyzję, pomaga w ulepszeniu modeli, zapewnieniu ich zgodności z przepisami i przygotowaniu lepszych produktów. Techniki „czarnej skrzynki”, takie jak uczenie głębokie (ang. deep learning), zapewniły przełomowe możliwości kosztem interpretacji. W raporcie — niedawno uzupełnionym o techniki SHAP — przedstawiamy, jak można zapewnić interpretację modeli bez ograniczania ich możliwości czy dokładności.
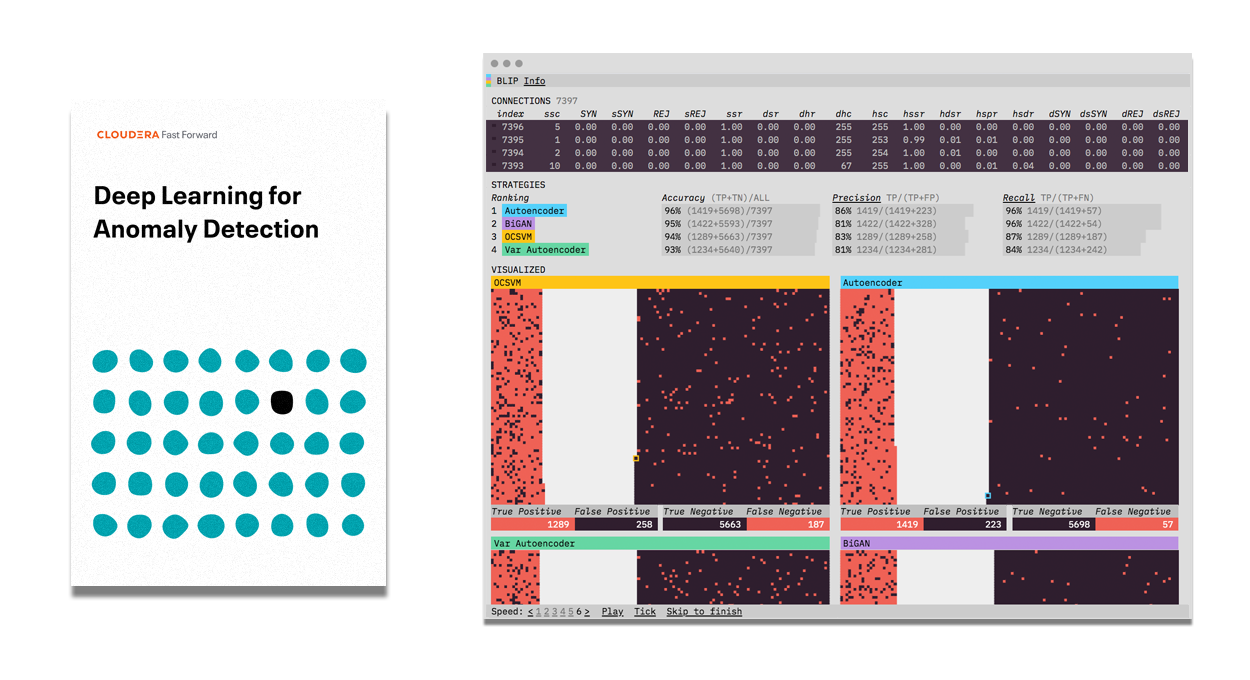
Uczenie głębokie w celu wykrywania nieprawidłowości
Sposoby zastosowania automatycznej identyfikacji nietypowych danych są niezliczone — od wykrywania oszustw po oflagowywanie nieprawidłowości w danych uzyskanych w wyniku przetwarzania obrazów. Proces ten może okazać się trudny, szczególnie gdy mamy do czynienia z dużą ilością złożonych danych. W raporcie omówiono podejścia do głębokiego uczenia (modele sekwencji, autoenkodery wariacyjne oraz generatywną sieć przeciwstawną) w kontekście wykrywania nieprawidłowości, ich zastosowania, wzorców wydajności oraz możliwości produktowych.
Uczenie transferowe na potrzeby przetwarzania języka naturalnego
Techniki przetwarzania języka naturalnego (NLP, ang. Natural Language Processing) wykorzystujące uczenie głębokie umożliwiają tłumaczenie języka, odpowiadanie na pytania i generowanie tekstów podobnych do tworzonych przez ludzi, wymagają jednak obszernych, kosztownych zestawów danych, drogiej infrastruktury i wiedzy specjalistycznej. Uczenie się przez przeniesienie znosi te ograniczenia poprzez ponowne wykorzystanie i dostosowanie rozumienia języka przez model. Uczenie transferowe dobrze sprawdza się w każdej aplikacji NLP. W tym raporcie pokazujemy, jak wykorzystać uczenie transferowe do budowy wysokowydajnych systemów NLP przy minimalnych zasobach.

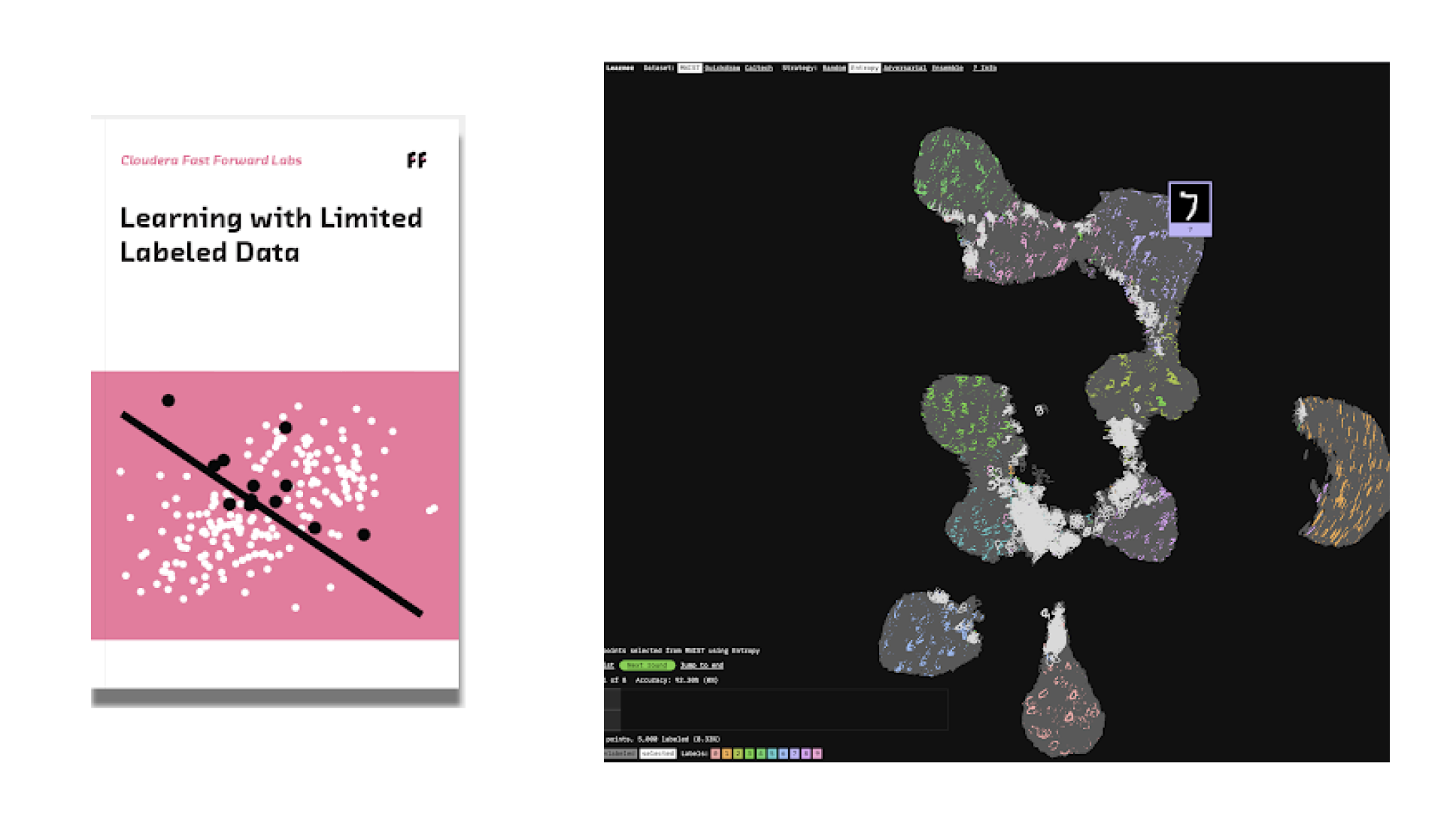
Uczenie z ograniczonymi oznaczonymi danymi
Możliwość realizacji uczenia z ograniczonymi oznaczonymi danymi rozluźnia rygorystyczne wymagania dotyczące oznaczonych danych w zakresie nadzorowanego uczenia maszynowego. W tym raporcie skupiono się na uczeniu aktywnym, technice, która opiera się na współpracy komputerów i ludzi w celu inteligentnego oznaczania. Uczenie aktywne zmniejsza liczbę oznaczonych przykładów wymaganych do wytrenowania modelu, oszczędzając czas i pieniądze, a jednocześnie pozwalając uzyskać wydajność porównywalną do tej, jaką dają modele trenowane za pomocą dużo większej ilości danych. Dzięki uczeniu aktywnemu przedsiębiorstwa mogą wykorzystać posiadane duże pule nieoznaczonych danych, zapewniając sobie nowe możliwości w zakresie produktów.
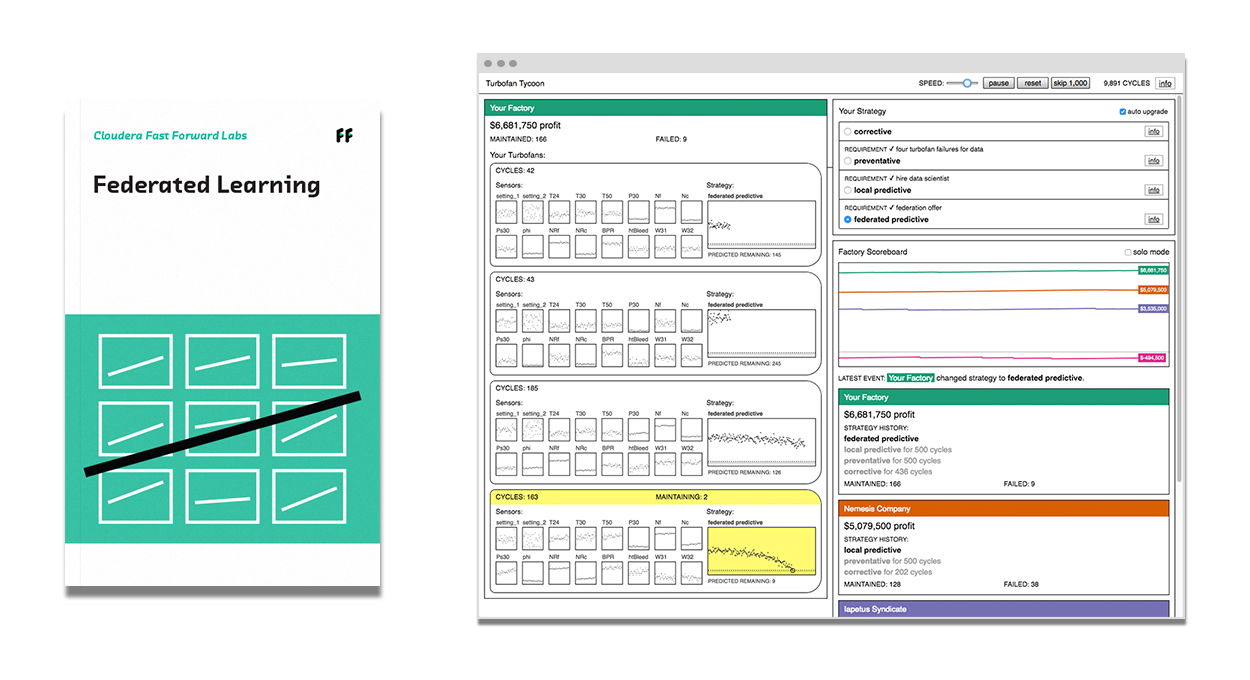
Uczenie federacyjne
Uczenie federacyjne umożliwia tworzenie systemów uczenia maszynowego bez bezpośredniego dostępu do danych szkoleniowych. Dane pozostają w swojej pierwotnej lokalizacji, co pomaga zapewnić prywatność i obniża koszty komunikacji. Uczenie federacyjne doskonale sprawdza się w przypadku smartfonów i urządzeń krawędziowych, opieki zdrowotnej i innych zastosowań wrażliwych w zakresie prywatności, a także zastosowań przemysłowych, takich jak konserwacja predykcyjna.
Zalecenia semantyczne
Internet jest źródłem mnóstwa inspiracji do czytania, oglądania i kupowania. Dlatego tak ogromnie wzrosło znaczenie algorytmów rekomendacji znajdujących przedmioty, które zainteresują konkretną osobę. W raporcie omówiono systemy rekomendacji wykorzystujące semantyczną zawartość elementów w celu dostarczania trafniejszych zaleceń w wielu branżach.

Podsumowywanie
W tym raporcie zbadano metody wyodrębniania podsumowań, czyli możliwości, która pozwala automatycznie podsumowywać dokumenty. Technika ta ma wiele zastosowań: od przygotowywania kwintesencji tysięcy recenzji produktów przez wyodrębnianie najważniejszych treści z długich artykułów prasowych po automatyczne grupowanie biografii klientów za pomocą typów osób.
Uczenie głębokie na potrzeby analizy obrazów — edycja 2019
Konwolucyjne sieci neuronowe (ConvNet lub CNN, ang. Convolutional Neural Network), zwane też splotowymi, wyróżniają się pod względem możliwości uczenia się interpretacji istotnych cech i pojęć występujących w obrazach. Dzięki temu są nieocenionym narzędziem do rozwiązywania problemów w wielu dziedzinach — od obrazowania medycznego po procesy produkcyjne. W raporcie wskazujemy, jak wybrać właściwe modele uczenia głębokiego na potrzeby analizy obrazów, a także przedstawiamy techniki usuwania błędów w modelach uczenia głębokiego.
Uczenie głębokie: analiza obrazów
W tym raporcie przedstawiono historię, stan bieżący i prognozy przyszłego rozwoju uczenia głębokiego, a także wyjaśniono jego zastosowania.

Metody probabilistyczne wykorzystania strumieni danych w czasie rzeczywistym
Odkąd wprowadzono zbudowane z krzywek i przekładni komputery analogowe, projektujemy systemy skoncentrowane wokół przepływu danych i krytycznych obliczeń. Podczas gdy filozofia naszych projektów pozostaje niezmienna, nasze ograniczenia inżynieryjne nieprzerwanie ewoluują. W ciągu ostatnich pięciu lat byliśmy świadkami pojawienia się „big data", czyli możliwości wykorzystania łatwo dostępnej infrastruktury do analizy bardzo dużych zbiorów danych w trybie wsadowym. Obecnie jesteśmy na zaawansowanym etapie opracowywania narzędzi, metod i technologii umożliwiających pracę ze strumieniami danych w czasie rzeczywistym.

Raporty tylko w ramach subskrypcji
Zaktualizowane wersje starszych raportów będą dostępne za darmo w przyszłości, więc zachęcamy do częstego sprawdzania.

Uczenie wielozadaniowe
Ten raport dotyczy uczenia wielozadaniowego — nowego podejścia do uczenia maszynowego, które umożliwia algorytmom równoczesne wykonywanie wielu zadań.
{kind=link}

Programowanie probabilistyczne
Przedstawiamy, jak programowanie probabilistyczne i wnioskowanie bayesowskie umożliwiają tworzenie narzędzi, które ułatwiają prognozowanie w celu efektywniejszego podejmowania decyzji.
{kind=link}

Generowanie treści w języku naturalnym
W tym raporcie rozważamy, jak systemy maszynowe mogą przekształcić wysoce ustrukturyzowane dane w treść w języku ludzkim.
Przeczytaj blog Fast Forward Labs
Bądź na bieżąco
Zapisz się, aby otrzymywać comiesięczny biuletyn, w którym znajdziesz najnowsze informacje na temat postępów w stosowaniu sztucznej inteligencji, a także o nowościach i wydarzeniach w naszej firmie.